So your competitor just got cited in a ChatGPT answer. You didn't. And the really frustrating part? You've never even seen them mentioned anywhere you'd actually read. It feels like they came out of nowhere.
I promise you, it’s not magic. It’s not fame, and it's probably not even a bigger content team. It’s a set of retrievable signals that made them look like the safest bet for that specific question. That's what brand authority means to an AI, and it’s a lot more engineerable than most of us founders think.
This is a framework for treating AI discoverability not as some vague reputation contest, but as an engine you can actually build. I'm a systems person. I have to turn chaos into a repeatable process, or I'll go nuts. This is that process.
The core idea is simple: brand authority in AI search is just your citation probability for a defined set of questions. That's it. You either engineer the signals that raise your probability (things like content structure, distribution, consistent messaging, and real proof), or you cede that ground to whoever does.
Brand authority isn't "fame." It's citation probability.
Forget all the vague "build trust" advice for a minute. An AI doesn't experience your brand like a person does. It's not impressed by your About page, and it doesn't remember that great webinar you hosted last quarter. It just processes signals. These signals are structured, retrievable evidence that you're the safest, most useful source to quote for a specific question.
The AI’s job: answer fast, safely, and with defensible sources
When someone asks Perplexity or ChatGPT, "What's the best way to reduce SaaS churn in the first 90 days?", the model isn't browsing the web like a curious researcher. It's running a pattern-matching game. It's asking, "Which sources have answered this type of question before in a way that's clear, trustworthy, and unambiguous?"
"Safe to cite" is the single most important filter. A model's biggest fear is getting something wrong in a way a user will immediately notice. So it gravitates toward sources that state things precisely, back up their claims, and show up in more than one place. This changes your content strategy. You're not writing to impress a reader with fancy prose. You're writing to be repeatable, to be the answer the AI can relay without risk.
Brand authority vs. topical authority (and why we all confuse them)
These two get mixed up all the time, and I've seen so many teams (including my own, in the early days) waste months of effort because of it. Topical authority is about depth. Do you cover a subject so well that models associate your name with that entire domain? Brand authority is about recognition. Does your company show up in enough credible places that models see you as a known entity, not just another random webpage?
Small teams usually can't afford to build both at once. Here’s the rule I use: if you're in a defined niche, chase topical authority first. Go deep and own your subject before you worry about a broader brand game. But if your category is crowded and the AI already has its favorite sources, you need brand authority signals. That means getting mentions, corroboration, and visibility off your own site to break into the top tier.
A simple mental model: “Can the AI confidently repeat this about us?”
If you only take one thing away, make it this. Before you publish anything, ask: could an AI accurately summarize this in one or two sentences and attribute it to my company with confidence?
If the answer is no because the content is vague, badly structured, or the claims are buried, it’s not going to become a citation. It'll get passed over for something crisper. This simple question should guide your messaging, your page structure, your proof points, and your distribution. It all comes back to being repeatable.
How AI engines discover your brand (and where authority comes from)
An AI "knows" you exist in two different ways. Understanding both helps you decide where to put your limited time and energy.
Training data pathway: long-term familiarity signals
When a model is trained on huge chunks of the internet, it builds a long-term map of the world. If your brand has shown up consistently over the years in articles, forums, directories, and discussions, you become part of its baseline understanding of your category.
This is the slow path. You can't publish a blog post today and change the model's training data. But it's why consistency is so much more important than volume. Showing up in the same way, saying the same things, over time, is how you become "familiar" to the next generation of models.
Live retrieval (RAG): what gets fetched and cited today
The much more actionable path is Retrieval-Augmented Generation, or RAG. This is what tools like Perplexity, Bing Copilot, and ChatGPT's browser mode use to get current information. They actively fetch web content to answer questions in real time. Your content can show up in an answer today if it's crawlable, well-structured, and directly answers the user's question.
This is where you should focus most of your immediate effort. Being findable, fresh, and relevant are the inputs that matter here.
Why Bing still matters (even if your customers "use Google")
I know, I know. You look at your analytics, see 2% of your traffic comes from Bing, and ignore it. I did too. That’s a mistake. Microsoft Copilot, Bing Chat, and a ton of other AI assistants pull their live data from the Bing index. If you're invisible to Bing, you're invisible to a huge slice of the AI answer ecosystem, no matter how good your Google rankings are.
Seriously, go submit your sitemap to Bing Webmaster Tools. It takes 30 minutes and unlocks a massive amount of AI surface area.
Why fan-out queries decide whether you show up
Modern AI doesn't just do one search for a complex question. It breaks it down. A question like "How do early-stage SaaS founders build organic growth?" gets decomposed into smaller queries: what are good channels for SaaS, what does organic growth mean, what are common mistakes, and so on.
If you have one monster blog post that touches on all those topics, you might get pulled in for one of them, at best. But if you have dedicated, well-structured pages for each of those sub-questions (what SEO folks call fan-out query coverage), you can appear in the results for multiple parts of the same original question. That multiplies your odds of being cited.
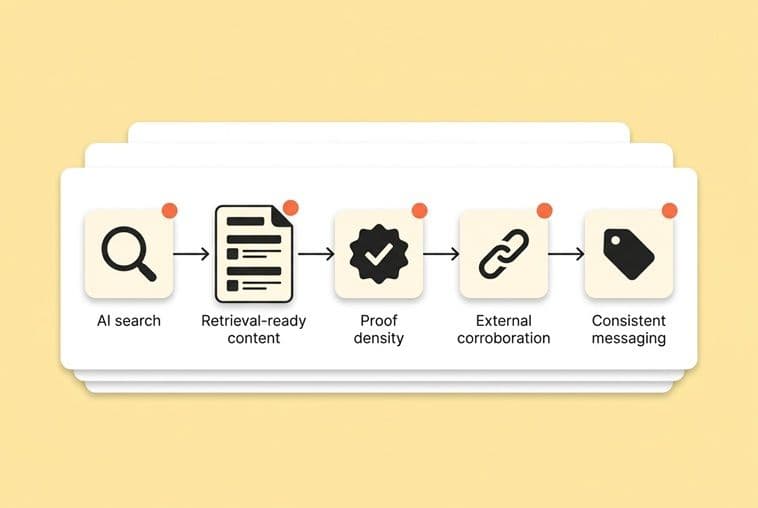
The 4 signal buckets an AI uses to "trust" and cite you
This is the whole system. To an AI, brand authority comes down to four types of signals you can control. Think of them as the four legs of a table.
Retrieval-ready content (structure, clarity, schema, static HTML)
Before your content can be citable, it has to be parseable. That starts with the basics. AI crawlers, just like Googlebot, love content that's rendered on the server or statically generated. They struggle with sites that rely on heavy client-side JavaScript. A simple test: turn off JavaScript in your browser and view your blog. If the content disappears, you have a problem that needs fixing.
Beyond that, add structured data. Using JSON-LD schema markup (especially Article, Organization, Person, and FAQPage types) is like giving the AI a labeled diagram of your content. It just removes any ambiguity. Pair that with clean heading hierarchies (H1 -> H2 -> H3) and concise paragraphs that make sense on their own.
Proof density (original insights, examples, clear claims with boundaries)
Generic content doesn't get cited. Not because an AI has good taste, but because it has thousands of more specific options. The thing that makes a page a "safe bet" for citation is specificity: original examples, precise language, and claims with a clearly defined scope.
You don't need a huge budget for proprietary research. You just need to be specific. Instead of saying your product "improves efficiency," say it "cuts review cycles by removing the back-and-forth between the writer and the SEO tool." Use real examples from your own experience. That's your structural advantage over some massive competitor that's just pumping out generic AI content. They weren't in the room when it happened; you were.
External corroboration (mentions, citations, reviews, community references)
An AI doesn't just read your site to learn about you. It reads what everyone else says about you. Every mention in a third-party article, every directory listing, every Reddit comment, and every partner page contributes to a web of corroboration.
This is where brand authority really separates from topical authority. You can be the world's leading expert on a topic, but if nobody else is talking about you, you'll lose the citation to a more well-connected (but less expert) brand. These external mentions are trust signals. They tell the model that other sources also think you're credible.
Consistent messaging (names, categories, descriptors, and “what you’re known for”)
This is the most underrated signal of all. If your website calls your product an "AI content assistant," your LinkedIn bio calls it an "AI writing tool," and a press mention calls it a "content automation platform," you’ve confused the model. You've split your own signal and made it harder for the AI to build a coherent picture of who you are.
Pick your terms. Standardize your category, your product descriptors, and the one or two things you want to be known for. Then use that language everywhere: your site, your social profiles, your directory listings, and any content you create. Consistency isn't boring. It's how you become retrievable.
My playbook for getting brand mentions (without hiring a PR firm)
"Get more brand mentions" is as useless as "do PR." It's not a strategy. As a lean team, you need repeatable plays, not vague goals. Here’s what’s actually worked for me.
The "mention inventory": where your category already gets cited
Before you create anything, map out where your category is already being discussed. Search for your competitors on Reddit, in newsletters, on comparison sites, and in podcast guest lists. You aren't looking for places to spam your link. You're identifying surfaces that already have your audience's trust and are likely already being cited by AI.
Your goal is a simple list of 15-20 places where a mention of your brand would feel natural and helpful.
5 repeatable mention plays a lean team can run
- Integration pages: For every tool you integrate with, create a dedicated page explaining how it works. These get linked by partners and show up for high-intent searches.
- Expert quote outreach: Find journalists writing about your space (Google News alerts are great for this) and offer them a sharp, specific quote. One quote in a real publication is worth ten blog posts for building external authority.
- Tactical mini-studies: Take data you already have (customer patterns, usage data) and publish a small "we looked at X and found Y" post. They get cited constantly because they're primary sources.
- Partner co-marketing swaps: Find non-competing tools with a similar audience and swap mentions in your newsletters or on your resource pages. It's a simple, high-leverage way to get seen.
- Community contribution: Genuinely answer questions in relevant Reddit, Slack, or LinkedIn communities. When it's natural, mention your framework or company. These indexed, third-party conversations are gold.
How to make mentions compounding (not one-off)
The biggest mistake is treating these plays as one-off tasks. The right way to think is in systems. Every piece of content you publish should have a distribution loop attached. When you publish an article, you should have a plan to repurpose it for social, pitch a quote from it, and get it linked from a partner.
This becomes easier when distribution is part of your default process. A tool like DeepSmith's Agent Library can help by automatically turning articles into social posts and newsletter blurbs. The goal is to turn one asset into five or ten mention surfaces without it feeling like a ton of extra work.
Measuring incremental impact: a lightweight attribution model
If you aren't measuring, you're just doing performative marketing. You need to know if your work is actually moving the needle on AI visibility. Here’s a simple way to start:
Build a prompt log. This is just a spreadsheet with 20-30 questions your ideal customer might ask an AI. Every month, run those prompts in ChatGPT, Perplexity, and Copilot. Track where you show up. After a couple of months of consistent mention-building, you'll start to see a connection between your efforts and your citation frequency. It’s not perfect, but it’s a hell of a lot better than flying blind.
How to build content clusters that AI can't ignore
The old "pillar and spoke" model isn't quite enough for AI retrieval. You need to think less about keywords and more about questions. Here's the upgraded approach.
Start with the question map, not the keyword list
Instead of starting with a list of keywords, start by mapping out the questions someone asks as they learn about your topic. Write them down just like a real person would say them. These are your fan-out query targets. These are the sub-questions AI engines look for.
For each topic you want to own, you should have dedicated pages that answer 8-12 of these specific sub-questions. I'm not talking about a mention in a 3,000-word behemoth. I mean indexed, crawlable pages where that one question is the star of the show.
The cluster blueprint: page types that win citations
Not all content formats are created equal. In my experience, these are the page types that consistently get pulled into AI answers:
- Definition pages: Simple "What is X" content gives the AI a clear, quotable definition.
- Comparison pages: "X vs Y" pages directly answer a common decision-making question.
- How-it-works pages: Step-by-step explanations are easy for an AI to relay as a process.
- Troubleshooting pages: Problem-first content shows up when users describe symptoms.
- Implementation checklists: Numbered lists are a format that AIs love to reproduce.
A healthy cluster has a mix of these, not just a pile of opinion pieces.
Interlinking for retrieval: how to guide crawlers through the cluster
Internal links are more than navigation; they're relationship signals. When you link from a sub-question page back to your main topic page, use anchor text that reinforces the topic. Link between related sub-questions. You want to create a dense web where any page in the cluster is only one or two clicks away from any other page.
Citation-ready formatting patterns
If you build good formatting into your drafting process, you'll save yourself so much pain later. That means using clear headings, putting short, concise answers right at the top of sections, and using tables or lists whenever you can. Content that is born citation-ready is much easier to scale.
Technical "AI crawler readiness" checklist (beyond static HTML)
You know static HTML is important. But here are a few other technical gotchas I’ve seen trip up even savvy teams.
JavaScript rendering and hidden content pitfalls
If your blog loads its main content using client-side JavaScript (which is common with some headless CMS setups), crawlers might see a blank page. Open your pages with JavaScript disabled. If your content vanishes, you have a rendering problem. You need to move to a solution like server-side rendering (SSR) or static site generation (SSG).
Pagination, canonicals, and faceted content
Splitting your content across multiple pages (like a blog archive) can dilute your authority if you don't use canonical tags correctly. Make sure all that "link juice" points back to the main page. Be careful that faceted navigation (like filtering by tags) doesn't create thousands of near-duplicate pages. Every bit of fragmentation weakens your signal.
Paywalls, gated content, and partial access patterns
Gating content is a totally valid business strategy, but a hard paywall makes your content invisible to AI. If you have a high-value asset you want cited, you need to use a partial access pattern. Expose enough of the content for a crawler to get a useful summary, and then gate the rest. You can stay retrievable without giving everything away.
Structured data basics that actually help
Don't get overwhelmed by schema. Just prioritize these: Organization schema to establish who you are, Article to signal what your pages are, Person if you're building a founder brand, and FAQPage or HowTo for question-and-answer content. Use the JSON-LD format. It won't fix bad content, but it removes ambiguity for crawlers on your good stuff.
Using AI ethically without publishing generic sludge (and what to do if you already did)
Let's be honest, we're all using AI tools. The goal isn't to pretend we don't, but to use them as a lever for quality, not a replacement for thinking. The real risk isn't using AI. It's publishing content that has no unique insight, no real-world examples, and no point of view.
The safe workflow: AI for synthesis, humans for claims and differentiation
Use AI for the grunt work. Let it summarize research, generate outlines, clean up transcripts, or draft a basic definition. But the core claims, the specific examples from your experience, the analysis of why it matters, and the final point of view have to be human. The AI synthesizes; you differentiate.
Differentiation checklist before you publish
Before any AI-assisted post goes live, ask yourself three questions:
- Point of View: Does this have a clear, non-obvious argument?
- Proof: Does it have specific examples or data that only I could provide?
- Precision: Is the language sharp, or is it full of vague business jargon? If you can't say yes to all three, it’s not ready.
Remediation: how to “humanize” and upgrade thin AI content
If you look at your blog and suspect it's full of generic content, don't panic. You just need to run an upgrade pass. Go through each article and inject proof. Add a real customer story, a specific data point you've observed, or a step-by-step walkthrough. Add a strong, opinionated intro and conclusion. Your goal with every edit is to add specificity and remove vagueness.
The 30-day founder plan: prove momentum without a big team
Okay, I know this can feel like a lot. It's not. You can build real momentum in a month by focusing on a few high-leverage actions. Don't try to boil the ocean.
Week 1: pick your category and standardize your messaging
Decide on the single, specific category you want to be cited for (e.g., "SaaS churn reduction for PLG"). Get your one-line description perfect. Then, go update your website homepage, LinkedIn company page, and founder profiles to use this exact language. This is a one-time fix that pays off forever.
Weeks 2–3: ship one fan-out cluster and run one mention loop
Just build one small cluster of 3-5 pages around your core category. For every single piece you publish, immediately run one mention play from the playbook. Pitch a quote, swap a mention with a partner, or answer a Reddit question. Tie creation to distribution.
Week 4: refresh, measure, and double down
At the end of the month, run your prompt log again. See any movement? Which piece of content worked best? Take that winner and find one more place to distribute it. This little loop, repeated over and over, is how you turn one-off tactics into a real growth system.