You searched for your core use case in ChatGPT last week. A competitor showed up. You didn't. Now your CMO is asking about "our AI search strategy," and you're holding a spreadsheet with three manual test results and no idea what to do.
Sound familiar? I've been there.
Here's the thing. Most advice about AI search optimization skips straight to tactics, like "add FAQ schema" or "write more helpful content." What nobody tells you is that tactics applied to an unmeasured problem just create noise. You'll burn a week publishing new content, run the same manual test three weeks later, and have no clue if anything changed or why. It's a recipe for burnout.
This article's argument is simple: before you try to improve your AI search presence, you need to audit it. And not just once. You need a repeatable system that produces specific outputs you can act on and defend to leadership. This is the playbook. We'll cover the whole system: how to choose prompts, score a baseline, catch factual errors before they spread, spot what competitors are doing right, and turn it all into a prioritized backlog your team can actually ship.
What is an AI search presence audit (and how is it different from an SEO audit)?
An AI search presence audit is a structured review of how AI platforms like ChatGPT, Gemini, Perplexity, and Google's AI Overviews represent your brand when buyers ask questions.
The goal isn't to see if your pages rank. It's to find out if you appear at all, what the AI says about you, if it's accurate, and how you stack up against competitors.
What "AI search presence" actually includes (mentions, citations, accuracy, sentiment, positioning)
I've found it's best to measure five things:
- Inclusion/visibility: Does your brand even show up when someone asks a relevant question?
- Citation frequency: Are you being linked as a source, or just mentioned in passing? A link is a much stronger signal.
- Accuracy: Are the claims AI makes about your product correct, current, and reasonably nuanced? This is where the real horror stories live.
- Sentiment and tone: Is your brand framed positively, neutrally, or just dismissed? Are you accidentally being positioned as the "budget option" when you're the premium choice?
- Competitive positioning: Which competitors appear alongside you (or instead of you)? How are those comparisons framed?
This last point is so important. AI systems love to create shortlists. Where you land in that cluster, and whether you're even included, shapes what buyers do next in a way that never shows up in a keyword rank report.
Where traditional SEO still matters, and where it won't answer the question
Look, the technical SEO basics like crawlability and site health are still table stakes. If an AI can't crawl your page, it's not going to show up in the training data or a retrieval pool. But that's where the overlap pretty much ends.
Your keyword rankings tell you nothing about whether an AI is citing your shiny new pricing page or a three-year-old blog post. Your domain authority doesn't predict which competitor gets recommended in a "best tools for X" answer. An AI audit asks different questions, so it needs a different way to measure.
Which AI platforms should you audit for B2B SaaS, and why results won't match?
Your results are going to be different on every platform. That's not a bug. It's a design difference you have to understand so you don't throw out inconsistent data thinking it's just noise.
The "core four" to include in your baseline (and when to add Google AI experiences)
I recommend starting with four platforms: ChatGPT, Perplexity, Claude, and Gemini. These cover what most B2B buyers are using for research, and they all behave a little differently. You can add Google AI Overviews after you've got a handle on the core four. Its behavior is a bit closer to traditional search and can be harder to isolate from standard ranking signals.
What changes by platform (citations, retrieval behavior, answer style, volatility)
I've seen teams get really spun up when one platform says something different from another. Don't fall into that trap. Each one gives you a different clue.
- ChatGPT (especially with browsing turned off) leans heavily on its training data, which means it often repeats outdated claims. This is your best place to audit for accuracy issues.
- Perplexity is great because it actively retrieves live sources and shows you the citations. It's my go-to for checking citation quality.
- Claude tends to give more nuanced, hedged answers. If your brand is missing here, it often means your general coverage or third-party signal is thin, not that you have a technical error.
- Gemini integrates with Google's index, so its answers can vary a lot from one run to the next.
The takeaway is this: run the same prompt across all four and treat their disagreements as data, not errors.
How do you choose the prompts to audit so you're measuring real buyer demand (not vanity queries)?
This is where most manual audits go completely off the rails. I see it all the time. Someone tests "what is [Brand Name]?" and either declares victory or defeat based on that one answer. That prompt tells you almost nothing about how real buyers find you.
Start with buyer questions, not keywords: a simple prompt taxonomy (problem → category → comparison → "best for")
You have to map your prompts to the buyer journey. Think about the questions they ask at each stage.
- Problem-aware: "How do B2B SaaS companies track AI search visibility?" or "Why isn't our brand showing up in ChatGPT?"
- Category-aware: "What tools help with AI visibility for content marketing?" or "What is generative engine optimization?"
- Comparison: "ChatGPT vs Perplexity for B2B research, which matters more?"
- "Best for" / shortlist: "Best AI visibility tools for small content teams" or "Which platforms should I check for AI brand mentions?"
Notice something? Your brand name isn't in any of those. The most valuable prompts are the ones buyers use before they know they're looking for you.
How many prompts to start with (and how to expand without boiling the ocean)
Start with 20–30 prompts spread across those four stages. It's enough to establish a real baseline without getting lost in the data. I usually aim for about five prompts per stage, covering my top two or three use cases.
Resist the temptation to create a list of 100 prompts right away. A small, clean prompt set that you actually rerun every month is so much more valuable than a huge one you run once and then abandon.
How to document prompts so you can rerun the audit and compare apples-to-apples
AI outputs are super sensitive to the exact phrasing, any persona context you give it ("I'm a content marketer..."), and even regional settings. If you change the prompt between runs, you can't tell if the result changed because of something you did or just because you asked a slightly different question.
For each prompt, you have to document: the exact phrasing, the platform, any persona context you used, the date you ran it, and whether web access was on or off. Store this in a shared spreadsheet that your whole team can access, not in your personal notes. Trust me on this one.
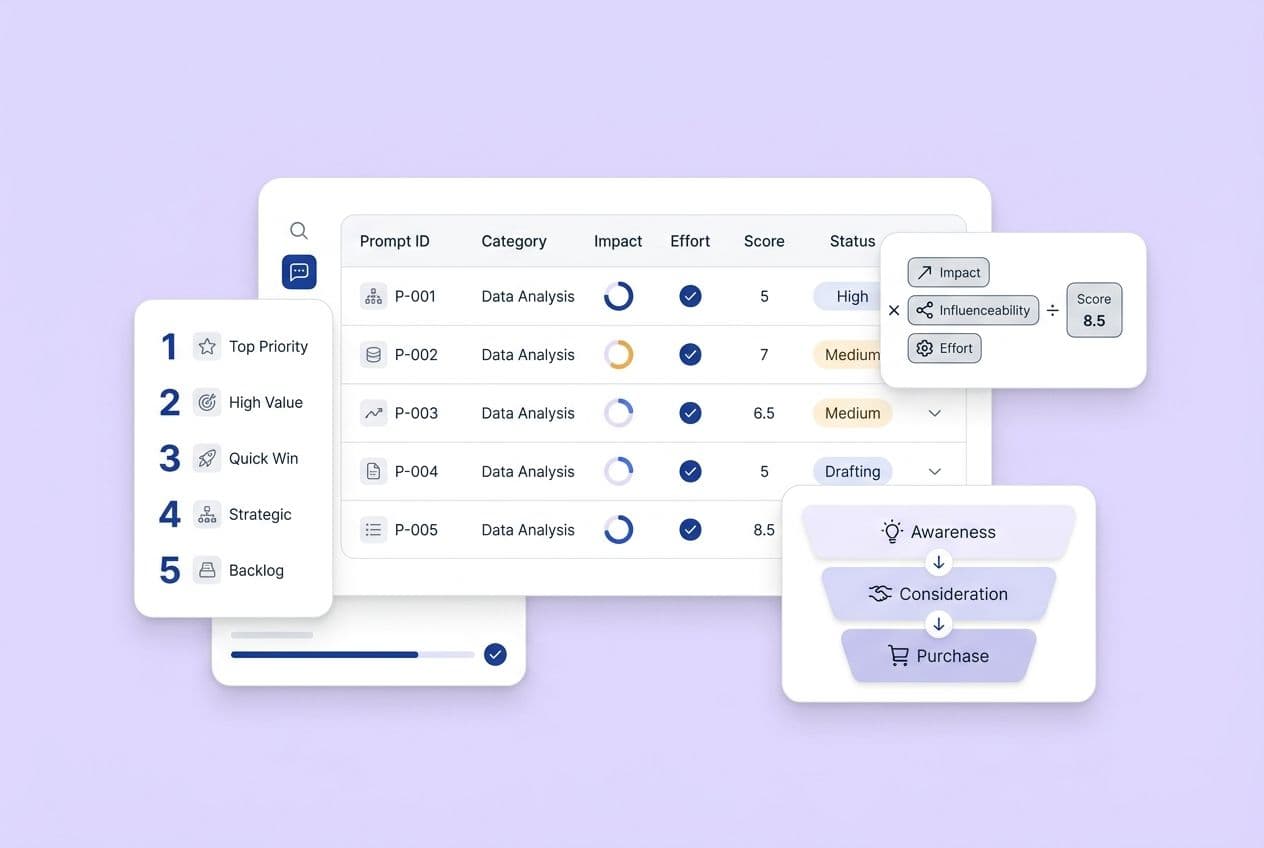
What to capture per prompt (mention, citation, rank/placement, quoted claims, recommended alternatives)
For every single prompt/platform combo, you need to log these things:
- Mentioned? (yes/no)
- Cited? (yes/no, with the source URL if it shows one)
- Position in response (first mentioned, listed third, not there at all)
- Quoted claims (what specific statements did the AI make about you?)
- Competitors also mentioned (who appeared with you or instead of you?)
- Sentiment (positive, neutral, dismissive)
This simple six-field structure is what turns a bunch of random tests into a real dataset.
What prompt tracking looks like when operationalized
Okay, let's be real. Manually running 25 prompts across four platforms is 100 checks. Doing that every month is a huge pain and quickly becomes unsustainable. We learned this the hard way. Operationalized teams automate this. (Full disclosure, we ended up building DeepSmith's AI Visibility — Prompts feature to solve this for ourselves). It lets you define the prompt set and then tracks mention and citation rates for you. But even if you're not ready for a tool, at least build a shared spreadsheet with locked prompt phrasing. That's the minimum for making your monthly runs comparable.
How do you score your baseline AI visibility (so "we're not showing up" becomes a measurable diagnostic)?
"We're not showing up" is a feeling. A scorecard turns that feeling into a diagnosis you can actually work with.
A practical scorecard: visibility, citation quality, accuracy, sentiment, differentiation, brand safety
I like to score each dimension on a simple three-point scale: Needs Work, Developing, or Strong.
| Dimension | Needs Work | Developing | Strong |
|---|---|---|---|
| Visibility | Not mentioned in most prompts | Mentioned in 30–50% | Mentioned in 60%+ |
| Citation quality | Cited from wrong pages or not at all | Sometimes cited from relevant pages | Consistently cited from high-value pages |
| Accuracy | Multiple errors or outdated claims | Minor gaps, mostly correct | Factually accurate across platforms |
| Sentiment | Neutral-to-dismissive framing | Generally positive with hedging | Consistently positive and specific |
| Differentiation | Clustered with wrong competitors | Correctly positioned, no differentiation | Clear positioning, differentiated framing |
| Brand safety | Negative associations present | No issues detected | No issues, monitored regularly |
Fill this out during your first audit. Then re-run it every quarter. Your goal isn't a perfect score. Your goal is a trendline moving in the right direction.
How to benchmark against competitors without getting fooled by one-off answers
Because AI outputs vary, a single test is just an anecdote. For competitive benchmarking, you have to run each comparison prompt three times per platform and look for patterns. If a competitor shows up in 8 out of 12 runs and you only show up in 2, that's a real signal. This kind of repeatable monitoring is what separates a one-off check from a real competitive intelligence program. This is another area where automation provides a huge advantage. For example, tools like our AI Visibility — Competitors feature let you monitor which competitor pages are winning citations, turning sporadic checks into continuous data.
The "citation quality" check: are you being cited from the right pages and sources?
Getting cited is good. But getting cited from an outdated blog post that doesn't reflect your current positioning is a totally different problem than not being cited at all. For every citation, ask: which specific URL is it pointing to? Is that your best page on the topic, or is the AI just grabbing whatever it can find with your brand name on it?
Perplexity shows you the source URLs directly. For other platforms, you can often just ask the model to list its sources. You might get a partial answer, but it's still useful.
How do you audit accuracy with a canonical fact registry (and stop AI from repeating the wrong story about you)?
This is the part that most AI optimization guides completely ignore, and it's often where the most damage is happening.
What a canonical fact registry is (and what it isn't)
A canonical fact registry is just a simple, internal document that lists the claims AI systems make about your brand, flags whether they're accurate, and provides the approved version of each claim.
This is not your brand style guide or your messaging deck. Think of it as a living checklist of specific facts that AI platforms either get right or wrong, with a designated owner and a schedule for review. It covers the claims that matter most in AI answers: your founding date, feature set, pricing, category, and key customer results.
What fields your registry needs (claims, proof/source, last verified, approved phrasing, "don't say")
Each row in your registry spreadsheet should have these columns:
- Claim (what the AI actually said)
- Status (accurate / outdated / fabricated / missing context)
- Approved phrasing (the correct version of the claim)
- "Don't say" (specific phrasings that are wrong or misleading)
- Source/proof (the URL on your site that proves the correct version)
- Last verified (the date someone last checked this)
- Owner (who's responsible for this claim)
You don't need a hundred rows to start. Ten to fifteen rows will cover the most important claims for most brands. Just build the minimum viable registry first.
How to run an "accuracy diff" from AI answers → registry → required fixes
When you do your prompt audit, copy and paste the AI's claims about your brand into a document. Then, go through your fact registry row by row and compare. Flag every mismatch: wrong feature, old pricing, incorrect founding story, a missing use case. Each mismatch then becomes a fix ticket. That could be a content update on your site, a PR clarification, or a new page you need to build to create an authoritative source for the correct info.
Maintenance: ownership, review cadence, and how it connects to product/PR updates
Designate one person to own the registry. Usually, that's you or your SEO lead. To make this a living document, the owner has to connect with other teams. We trigger a review by syncing with product marketing's launch calendar, PR's announcements, and any messaging updates from legal. At a minimum, review it quarterly when you rerun the full audit. If you don't, the errors you fixed in one audit will quietly creep back in after the next model update.
What content structures actually increase AI citation likelihood (beyond "write helpful content")?
"Helpful content" is the right idea, but it's too vague. AI systems extract information in specific ways, and if you format your content correctly, you can make that extraction a lot easier for them.
The citation-ready formatting checklist (direct answers, lists, tables, definitional blocks)
The pages that consistently earn AI citations tend to share these traits:
- Direct answer in the first 100 words: AI systems love to pull the clearest, most direct answer to a question. Give them the answer first, then explain it.
- Numbered or bulleted lists: Scannable structure is extractable structure. If you're making a point with multiple parts, put it in a list.
- Definition blocks: For any term your buyers might ask an AI to explain, include a clear definition: "X is a [type] that [does Y] by [mechanism Z]."
- Tables for comparisons: Buyers ask a ton of comparison questions. If you have comparison content, put it in a table. It's practically begging to be cited.
- Step-by-step "how to" structures: Sequential steps are incredibly easy for an AI to lift and present as a neat, clean answer.
Schema and metadata: what to review and why it may affect extraction/citation
FAQ schema, HowTo schema, and Article schema help AI systems understand the structure of your pages. They aren't magic, but pages with bad structure and metadata are less likely to get pulled in the first place. For your most important pages, audit the title tag clarity, meta description, and the H1 to make sure it directly answers the question a buyer would ask.
Page patterns that tend to win citations (comparison tables, "how to," troubleshooting, explainer + steps)
In practice, I see a few page types win citations over and over:
- Comparison pages ("X vs Y" or "Best [category] tools")
- How-to guides with clear, numbered steps
- Troubleshooting content that matches those problem-focused queries
- Explainer pages that define a concept and then walk through the steps
If you don't have any of these for your core use cases, that's the first content gap your audit should identify.
Third-party citation seeders: where off-site mentions can influence AI answers
Your website isn't the only thing these AIs read. They also look at community posts, industry articles, podcast mentions, analyst reports, and Reddit threads. If AI is consistently ignoring your brand even when your own content is solid, the problem is often a lack of third-party signal. This is where PR, guest content, and community engagement start to pay real dividends for AI visibility.
How do you detect and remediate AI brand safety risks before they spread?
Most teams I talk to skip this part until something goes horribly wrong. By then, the wrong answer has been served to thousands of potential buyers.
The brand safety checklist (negative framing, brand collisions, outdated narratives, unsafe adjacency)
When you run your prompts, look for these specific risks:
- Negative framing: Is the AI describing your product with words like "limited," "basic," or "expensive" without any source?
- Brand collisions: Is your brand name being confused with a competitor or a totally different company with a similar name?
- Outdated narratives: Is the AI talking about your Series A pricing, a feature you killed two years ago, or a market position you've moved on from?
- Unsafe adjacency: Is your brand being mentioned in the same sentence as a controversy or negative event that has nothing to do with you?
Remediation paths: when to update your site, publish clarifications, or build authoritative third-party references
Fixing these issues isn't just a content job. You have to match the fix to the root cause and pull in the right people.
- Outdated info from your own site: This one's on you. Update the page and submit it for reindexing.
- Claims from third-party sources: Create a strong, authoritative correction page on your own domain and have your PR team pursue corrections where possible.
- Brand collision: Publish content that explicitly clarifies the difference. Good positioning helps the AI disambiguate.
- Negative framing with no source: This is the hardest. The best you can do is build a body of positive, specific third-party mentions to displace the negative framing over time.
How to document incidents and track whether fixes worked
Keep a running brand safety log right next to your fact registry. For each issue, log the platform and prompt, severity (low/medium/high), the fix you applied, and the date you finally see the issue disappear. This log is also your evidence for leadership when AI brand safety becomes a topic in the boardroom, which it eventually will.
How do you turn the audit into a prioritized remediation backlog (and prove it's worth doing)?
An audit that just lives in a Google Doc is a waste of time. It has to produce work orders. It has to make things happen.
Prioritization framework: impact (prompt value) × fixability × risk × effort
I score each finding on four factors, on a simple 1–3 scale.
- Prompt value: How important is this query? High-intent prompts get the highest score.
- Fixability: Can you fix this on your own site, or do you need third-party help? On-site fixes score higher.
- Risk: Is this a brand safety issue or just a visibility gap? Safety issues get a bump.
- Effort: How long will this take? Lower effort beats high effort if the impact is equal.
Multiply or add up the scores. Then just work your way down the list.
What "good audit outputs" look like: scorecard, prompt library, fix backlog, owners, SLAs
When you're done, the deliverable for your audit should be these five things:
- Baseline scorecard (the six-dimension table, all filled out)
- Prompt library (your documented prompts and all their capture fields)
- Canonical fact registry (claims, status, approved phrasing)
- Prioritized fix backlog (the finding, the fix, the owner, the due date)
- Brand safety log (incidents, severity, status)
And each of those five artifacts needs a clear owner to be effective.
Scaling for large sites: sampling rules, page clusters, and automation targets
If you have thousands of pages, you can't audit every single one. You have to sample. Group your pages by topic or intent, pick the top two or three pages in each cluster for a citation quality review, and rotate the sample every quarter. Focus on the pages that are already showing up in AI citations; those are your highest-leverage assets.
How to report progress and ROI without overclaiming attribution
Let's be honest: direct attribution from AI visibility to pipeline is really hard to measure right now. Don't pretend you can. Leadership will see right through it. Instead, report on the things you can measure.
- Trendlines: Are your mention and citation rates going up, staying flat, or going down?
- Competitive deltas: Are you closing the gap with your key competitors?
- Risk reduction: How many brand safety issues did you find and fix?
- Content output: How many new pieces of content did you publish based on the audit?
Frame it like this: We built a measurement system for a new channel that didn't have one. Here's what we're seeing, and here's what we're doing about it. That's a story you can defend.
Closing the loop from insights → content production
An audit's findings have to become actual work. The gap between identifying a problem and shipping a fix is where most of these programs die. If you're managing this in spreadsheets, you have to build a direct handoff step: audit finding → content brief → writer assignment. (We built this into our Content Studio + Topics tools to close that loop, but you can manage it manually). Whatever your process, someone has to own that handoff. Without it, the audit dies in a doc every single time.
How to keep the audit current as models change
Models update constantly. An accurate answer from March might be wrong by June. You have to build a quarterly rebaselining checkpoint into your calendar. Rerun your full prompt set, rescore your scorecard, and check your fact registry against what the AIs are saying now. When a big model release happens (like GPT-5), treat it as a trigger for an extra audit of your most important prompts. Dashboards like our AI Visibility — Overview can surface these shifts for you, but the key habit is reviewing your KPIs monthly so you can investigate any big drop or spike before it becomes a problem.
Turn your audit into a repeatable system (not a one-time project)
The hardest part of this isn't running the audit once. It's turning it into something your team can repeat without burning out.
Start with the minimum viable version. That means 20–30 prompts, four platforms, the six scorecard dimensions, and a basic fact registry with your ten most important claims. Run it. Document the outputs. Build your first fix backlog. Then put a reminder on your calendar to do it all again next quarter.
The teams that win at AI visibility aren't the ones running more experiments. They're the ones running a system. A defined prompt set. A maintained registry. A prioritized backlog. Monthly metrics your CMO can actually understand. That's the difference between "we looked into AI search" and "we have an AI visibility practice."
Start the audit before you start optimizing. Everything else will follow from that.