You searched for your brand's core use case in ChatGPT last week. A competitor showed up. You didn't.
That hurts. It's not a content quality problem, either. You've been doing all the right things: publishing consistently, earning decent rankings, and keeping your SEO fundamentals solid. But here's what I had to learn the hard way: "good SEO" and "AI citation-worthiness" are not the same thing. The playbook that got you on page one won't automatically get you cited in an AI answer.
AI search trust isn't won by chasing new keywords. It's earned by making your brand verifiable and consistent across the web, then publishing answer-first content that an AI can confidently grab and cite. The brands I see winning AI citations treat their visibility as a system: entity, evidence, extraction, and ecosystem all working together. The good news? Your lean SaaS content team can build this system without a massive PR budget. It just requires a different mental model than the one your current SEO program is running on.
What does it mean for an AI search engine to "trust" your brand?
When Google ranks a page, it's making a bet that the page is relevant and credible enough for a searcher. The user does the final bit of work to decide. But when an AI search engine cites your brand in an answer, it's vouching for you. It's saying, "This is the answer, and this brand is a reliable source for it." That's a much higher bar to clear.
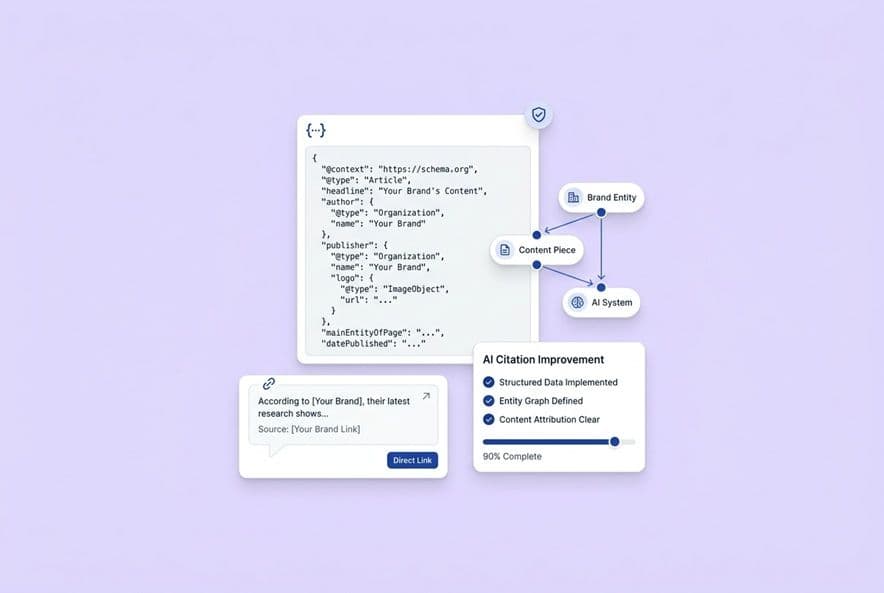
Practically speaking, AI trust is cite-ability. A model trusts your brand when it can confidently connect a clear, verifiable claim to a specific company (that's you). For this to happen, three things have to line up. The model has to know your brand exists as a single, coherent entity. It needs evidence that you have legit expertise on the topic. And it must be able to extract a clean answer from your content without screwing up its meaning.
Trust vs relevance: why "good SEO" can still result in zero AI citations
A page can be #1 on Google and get completely ignored in AI answers. We've had this happen, and it's maddening. Why does it happen? Traditional ranking rewards relevance signals like keyword alignment and backlinks. AI citation rewards extractability and verifiability.
A well-optimized article that buries its main point in the sixth paragraph is easy for Google to rank but impossible for a generative model to cite. An AI can't paraphrase buried nuance without a high risk of getting it wrong, so it just cites someone else's clearer, more direct answer instead.
Mentions vs citations: the two outcomes you should track separately
You need to track two different things here. A mention is when your brand name shows up in an AI response, even without a link. A citation is when the AI attributes a specific point to your content and links back to your page as the source.
Citations are way harder to earn and far more valuable; they mean the model sees your content as authoritative. Tracking both lets you see if you're building general awareness (mentions) or real authority (citations), and it shows you where you're leaking opportunities.
Which signals actually make AI engines more likely to cite you (the 4-layer model)
When most teams first try to crack AI visibility, they just start collecting random tactics. They add some schema, tweak a headline, pitch a podcast. We did this too, and nothing compounded. That's because each tactic addresses a different layer of trust. If a foundational layer is broken, working on the upper layers is a waste of time.
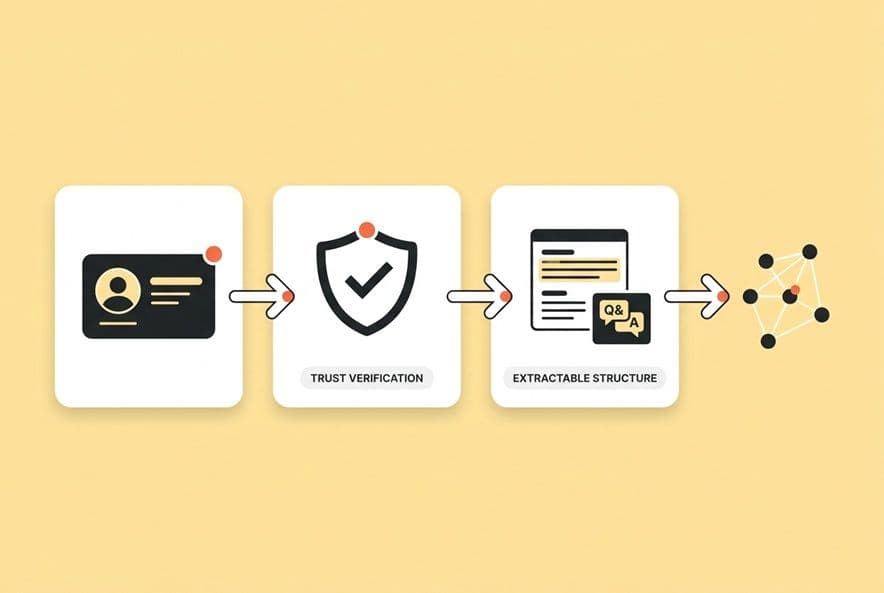
Here's the framework that finally worked for us: Entity → Evidence → Extraction → Ecosystem. You have to work them in order.
Entity: make your brand unambiguous across the web
Before an AI can cite you, it has to know who you are, consistently and without any confusion. "Entity clarity" just means that when a model sees your brand name on different sites, it can confidently connect them all to the same organization with the same expertise.
Here's where it usually breaks down: your LinkedIn "About" section describes your company differently than your website. Your Crunchbase profile uses an old category. Your author bios on guest posts don't link back to your site. You have to fix this first. Create a canonical brand description (one sentence, one paragraph). Then, check that your company category, founding year, location, and value prop are identical on your site, Google Business Profile, LinkedIn, Crunchbase, G2/Capterra, Wikipedia (if you have one), and every single external author bio. A model that can't figure out who you are won't trust you enough to cite you.
Evidence: prove claims with sources, experience, and verifiable details
You've heard of E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness). It matters because AI models are trained on the web's credibility signals, and those signals reward demonstrated expertise, not just asserted expertise.
The practical translation? Stop saying "we're experts in X" and start showing why. We have a rule on our team: every article needs a "proof asset." A proof asset is any content element that replaces a vague claim with a verifiable specific. This could be a methodology you've named, original data from a customer survey, a proprietary framework, or author credentials that prove the writer has real-world experience. Every article you publish should have at least one.
Third-party validation lives here, too. Reviews on G2 or Capterra, mentions by industry analysts, and press coverage all signal that other people confirm your expertise. You don't need a feature in Forbes to make progress. Honestly, three strong G2 reviews from named customers describing a specific use case carry more signal than a generic roundup mention.
Extraction: format content so AI can lift correct answers without distortion
This is where your team can get the fastest wins, I promise. AI models find answers by scanning for clear, direct statements. If your content is buried in long, narrative paragraphs, the model has to interpret it. Stripping context often leads to inaccuracy, so models just avoid the risk by not citing you at all.
The fix is to use an answer-first structure. Every section of every article should open with the main point, then support it. Not "SEO has evolved significantly..." but "AI search citations require entity clarity before keyword relevance. Here's what that means."
Within the body of your article, look for places where a reader might have a follow-up question. Add short Q&A blocks right there, like a bolded question followed by a two or three-sentence answer. These are perfect extraction targets. You should also clearly label key terms and definitions and use numbered steps for any process. And please, cut the hedging language ("it could be argued that..."). It makes your claims feel weak and unciteable.
Ecosystem: build trust outside your blog (without turning into a PR org)
AI models learn about your brand from the entire web, not just your website. When other credible sites mention, quote, or link to you, it adds to the model's confidence that you're a real deal.
For a lean team like ours, guest articles on publications our buyers actually read are the highest-leverage move. One solid contributed piece per quarter does more for your AI ecosystem signals than twenty social media posts. Podcast appearances are also great, especially when you're credited as a named expert. They register as entity validation. Even just getting quoted in someone else's roundup post reinforces that you exist and have something valuable to say. The goal isn't massive coverage. It's diverse and consistent evidence that you're part of the conversation.
How can a smaller SaaS brand build AI trust signals quickly (without a PR budget)?
The 30–60 day window is real. No, you won't build enterprise-level domain authority in two months. But you can make targeted progress that starts moving your citation rate up if you focus on what you can control.
Start where you can be the "primary source" (not where the volume is)
Trying to win high-volume, competitive topics is a trap. You'll be fighting established brands with years of backlinks. Don't start there. Start with the questions where your brand has a genuinely unique perspective. Think about your product's niche use case, your specific implementation methodology, or the problem you solve in a way nobody else does. These are your primary source topics.
Brainstorm 10–15 questions that buyers ask that you could answer better than anyone else because it's your world. These are your first AI visibility targets. Write thorough, evidence-backed articles on each one, and structure them for extraction. You won't win any search volume trophies right away, but you will start building a real citation footprint.
Build a "proof library" you can reuse across articles
Every article needs credibility signals, but creating them from scratch every time is a path to burnout. Instead, build a proof library. This is just a shared document that catalogs reusable proof assets for your team.
Include things like your named methodologies, original data points, quotes from your founder, specific (but anonymized) customer use cases, and key third-party stats you often cite. When a writer starts an article, they just pull from the library. This was a game-changer for our small team. Every piece gets richer, faster, and your credibility becomes operationalized.
Create a consistency checklist for your top 10 brand surfaces
This might feel too simple to matter, but it does. Pull up your brand description on these 10 surfaces: homepage, LinkedIn About, Crunchbase, G2/Capterra, Twitter/X bio, Wikipedia, your most-shared guest posts, podcast show notes, author bios, and your Google Business Profile. Compare them all to your canonical brand description, flag every little mismatch, and fix them in one afternoon. It's the highest-leverage, lowest-effort task on this list. Entity consistency is the foundation, and it's broken at almost every company that has ever changed its messaging.
Use distribution to manufacture "multi-channel visibility" from one article
Every article you publish should show up in at least three places: the blog post itself, a LinkedIn post that pulls out the most citable insight, and a mention in your newsletter. This isn't just about reach. It's about creating consistent, multi-platform evidence that your brand is the source of that insight.
Let's be honest, distribution is usually the first thing to fall off the list when you're busy. The only way it happens is if you build it into your workflow. We use DeepSmith's Agent Library to generate LinkedIn posts, newsletter sections, and social variants from each article in our voice. It turns distribution into a quick approval step instead of another project we have to start from scratch. This is how you create the multi-channel footprint AI models read as authority.
What content structures make your pages easiest for AI to extract and cite?
Okay, let's get into the nitty-gritty. Structure isn't just about formatting; it's the architecture of your answer. AI models can pull clean answers from pages where the hierarchy is obvious and the claims are direct.
The "answer-first" section opener formula (and what to avoid)
Open every H2 section with a direct, one or two-sentence answer to the question in the heading. No warm-up. Then, use the rest of the section to explain and give examples. This is the exact opposite of how most of us were taught to write, where we build up to a conclusion. For AI extraction, the conclusion has to come first, or the model will likely miss it or mess it up. Avoid starting sections with throat-clearing phrases like "Before we dive in..." and don't split your main answer across multiple paragraphs.
Q&A blocks, mini-FAQs, and "model-ready" definitions inside the body
The FAQ at the end of an article isn't the only place for Q&A. Anytime a reader might have a follow-up question inside a section, answer it right there in a bolded Q&A format. For example: "What's the difference between a mention and a citation? A mention is any time your brand name appears in an AI response. A citation is when the model attributes an answer to you and includes a link." It's clean, direct, and perfectly extractable. Do the same thing with definitions whenever you introduce a key term like "entity clarity" or "proof asset."
Comparison tables that win citations (templates to use)
AI models love tables. They are like information candy for them because they compress complex information into a structured format. We've found three patterns work best: a criteria comparison (which approach to use, and when), a priority matrix (what to do first vs. later), and a trade-off table (the pros and cons of different options). Try to keep tables to five rows or fewer; longer tables can get misread. And always include a "when to use this" column if you're comparing options.
Content clusters + internal links as a trust multiplier
A single great article can earn you a few citations. But a cluster of 8 to 12 interlinked articles on related topics is how you earn category authority. That's when models start treating you as the go-to source for a whole subject.
Build these clusters around the topics where you want to own AI answers. Every article in the cluster should link to at least two others, and your main pillar piece should link out to all of them. This reinforces your entity signal. The model sees a consistent brand making consistent claims across a web of interconnected content on the same subject.
Which schema markup types are most useful for AI search trust—and how should you prioritize them?
Schema advice is often either too vague ("just add schema!") or way too technical. Don't get scared off. For a small team, you only need to focus on a couple of things to start.
Schema that clarifies "who you are" (entity/organization-level)
Start with Organization schema on your homepage. This tells AI systems exactly who you are: your official company name, URL, logo, social profiles, and so on. It's foundational. If your team publishes content with author bylines, you should also add Person schema to author profile pages with the author's name, credentials, and links. These schemas reduce the ambiguity that makes AI models hesitant to attribute claims to a source.
Schema that clarifies "what this page answers" (content-level)
For articles that have those Q&A blocks we talked about or a closing FAQ section, FAQPage schema is your friend. It marks up the question-answer pairs so models can extract them perfectly. For any content that's a step-by-step guide, HowTo schema makes the sequence machine-readable. Finally, basic Article schema with the datePublished, author, and publisher fields helps models check for recency and credibility.
Here's the priority: Organization + Article first. Then FAQPage on any Q&A content. Then HowTo on your process-heavy articles. Ignore the rest for now.
Common schema mistakes that reduce trust
The fastest way to lose an AI's trust is to mark up content that isn't actually visible on the page. It looks manipulative and can get you penalized. Also, don't add FAQPage schema to a page with no real questions and answers, and don't leave required fields empty in your Article schema (like the author or date). Incomplete or incorrect schema is often worse than no schema at all.
A simple implementation workflow for lean teams
For each new article: (1) Confirm Article schema is applied automatically by your CMS. (2) If the article has a FAQ, add the FAQPage markup before you publish. (3) Always validate the page with Google's Rich Results Test before it goes live. For your existing site, audit the Organization schema on your homepage first. Then, go back through your 10 highest-traffic content pages and clean them up. One clean implementation is worth more than 20 broken ones.
How do you measure AI trust progress (and connect it to engagement and outcomes)?
If you don't measure, you're just guessing. We were guessing for way too long. This is the part that turns AI visibility work from a random collection of tactics into a real discipline.
Build a prompt map: the questions you want to be the cited answer for
Grab a spreadsheet. List 20–30 prompts your buyers would realistically type into an AI engine. Include prompts about their problems, comparisons between solutions, and basic definitions. These are your tracking targets. To start, run them manually across a few AI engines every week. Note whether your brand is mentioned, cited, or absent. Start with the engines most used for B2B research, like ChatGPT and Perplexity, then add Google AI Mode. You can expand to Gemini and Claude once you have a baseline.
Of course, manual tracking gets old fast. We built DeepSmith AI Visibility — Prompts to track our mention and citation rates systematically across all these engines, so we can see what's working without spending hours a week copying and pasting.
Tie citations back to pages and content patterns
When you earn a citation (pop the champagne!), ask yourself: what's on that page that made it cite-worthy? Map your citations back to the specific pages that earned them and look for patterns. Do all the cited pages have answer-first openers or embedded Q&A blocks? This is how you stop guessing and start building a repeatable playbook. Do the same for your competitors. When a competitor gets cited, go read their page to understand its structure and what proof they used. Tools like DeepSmith AI Visibility — Competitors can help by tracking which of their pages are winning citations, which gives you a constant stream of intel for your own content calendar.
Use engagement as a leading indicator (carefully)
Time on page and scroll depth are decent signals that your content is useful, and useful content is more likely to be cited. But don't fall into the trap of treating engagement as a direct proxy for AI citations. A page can get amazing engagement from your email list but earn zero citations. Use engagement as a quality signal, not a citation predictor. If a page has strong engagement but low citations, the problem isn't the content quality. It's probably an issue with extractability or entity clarity.
How do you keep up as AI models change (without rewriting your strategy every quarter)?
Here's the secret: you don't. You don't try to keep up with every little change. You anchor on the things that don't change.
What changes often (interfaces, engines, SERP features) vs what stays stable (verifiability, clarity)
AI interfaces change all the time. But what the models fundamentally reward doesn't change nearly as fast: a clearly identified, verifiable source making a specific, well-supported claim in plain language. If you build your program around that core principle, interface changes become minor adjustments, not full-blown strategy overhauls. Keep your entity layer tight, your evidence strong, and your content extractable. The underlying mechanics of trust are far more stable than the surface-level features.
An ethical AI content governance checklist that protects trust
Using AI to help with content is fine; publishing unvetted AI drafts is how you destroy the trust you're working so hard to build. This isn't about being a purist; it's about protecting your brand. Here's our minimal checklist:
- Human authorship review: A named person with real expertise reads and approves the final content.
- Claim verification: Every single fact or statistic is checked against a credible source.
- Sourcing transparency: If you cite data, link to the original source. Always.
- Product claim boundaries: Your brief or content system should define what's claimable so AI doesn't start hallucinating features for you.
- Update logs: Add a "Last reviewed" date to your evergreen articles and actually review them on that date.
This governance layer is a trust signal in itself. Brands that publish carefully are exactly what AI models are being trained to prefer as citation sources.
A 90-day operating cadence: audit, test, publish, iterate
Here's the 90-day loop we run. It runs alongside your existing content program, so you don't have to stop what's already working.
Month 1 (Audit): Fix entity consistency across your top 10 brand surfaces. Implement Organization and Article schema site-wide. Build your prompt map, run your baseline citation checks, and identify your first batch of primary source topics.
Month 2 (Test and Publish): Publish 3-5 articles on those primary source topics using answer-first structure, Q&A blocks, and proof assets. Repurpose each one into LinkedIn and newsletter content. To keep this pace without burning out the team, a repeatable workflow is key. We use DeepSmith's Content Studio to generate structured drafts, which lets our experts focus on review and accuracy, not manual assembly.
Month 3 (Iterate): Review which pages earned citations and what they have in common. Run a competitor citation check to spot gaps. Update a few high-traffic articles that aren't being cited yet. Pitch one guest article. Then, repeat the cycle.
Good, well-structured, evidence-backed content wins in both traditional search and AI search. This work just makes your existing foundation even stronger.
Build your AI trust system (and track whether it's working)
So, the framework is here: entity clarity first, then evidence, then extraction-optimized structure, and finally, ecosystem distribution. And the 90-day cadence gives you a manageable sequence that won't overwhelm your team.
But knowing what to do isn't the hard part. The gap most teams fall into is not measuring whether any of it is actually working. Without tracking your prompts, you're flying blind. Without watching competitors, you're missing out on free intel. And without a repeatable content workflow, every article remains a heroic effort.
We built DeepSmith to solve this problem for our own team. You can track citation rates across all the major engines with AI Visibility — Prompts, see what's working for your competitors with AI Visibility — Competitors, and produce AEO-structured content at scale with our Content Studio and Agent Library. It turns a messy process into a system.
The brands that win in AI over the next year won't be the ones who read the most articles about it. They'll be the ones who built a system and ran it, week after week. This is a good place to start.