To earn consistent AI citations, your site needs to pass three gates: Access (AI crawlers can fetch your content), Identifiers (stable canonicals and entity pages remove ambiguity), and Extraction (structured, passage-ready content gives systems something to quote). These aren't new tactics. They’re just technical SEO discipline applied at the entity and passage level. Get all three right, and you've built a site that AI systems can recognize, retrieve, and cite.
I know the feeling. You’ve done all the work: regular publishing, a solid keyword strategy, optimized titles. And you still open ChatGPT or Perplexity, type in your core use case, and watch a competitor get cited instead. It feels arbitrary and frustrating. You don't have a system for understanding why, and every "optimize for AI" article gives you the same generic advice about "adding schema" with no real prioritization or sense of what actually breaks.
Let's fix that. LLM visibility isn't some separate, mysterious SEO track. It’s the same technical foundations like canonicals, structured data, and crawl access, just executed with more precision.
This checklist is organized for content leads who need to hand specific, actionable tasks to their SEO, dev, and content folks. The results are probabilistic and require iteration; there's no magic switch to flip. But I can tell you from experience: teams that treat their site like a governed knowledge system will always outperform teams that treat this as a one-time setup project.
What Does "LLM Retrieval" Mean for a SaaS Website (and Why Isn't Traditional SEO Enough)?
LLM retrieval works differently from the keyword ranking we're all used to. When a user asks a question, the AI system breaks down the query, figures out the concepts involved, pulls relevant passages from its index, and synthesizes an answer. Then it often cites the sources it used.
Here’s the key difference that changes everything: AI engines cite passages, not pages. A system might pull three perfect sentences from your H2 intro and completely ignore the rest of the article. This changes what "optimization" means. Page-level authority still matters, of course, but the clarity and formatting of individual sections often determine whether your content gets extracted and cited.
The model I use for this has three layers:
-
Access: Can AI crawlers like GPTBot, ClaudeBot, and PerplexityBot actually fetch your core content? No JavaScript blocking, no
robots.txtexclusions on key page templates. This is table stakes. -
Identifiers: Do you have stable, unambiguous references like canonical URLs and dedicated entity pages? Without them, the signals about your expertise get fragmented and lost.
-
Extraction: Is your content structured in a way that makes individual claims easy to lift and attribute? This means clear sections, consistent terms, and schema markup.
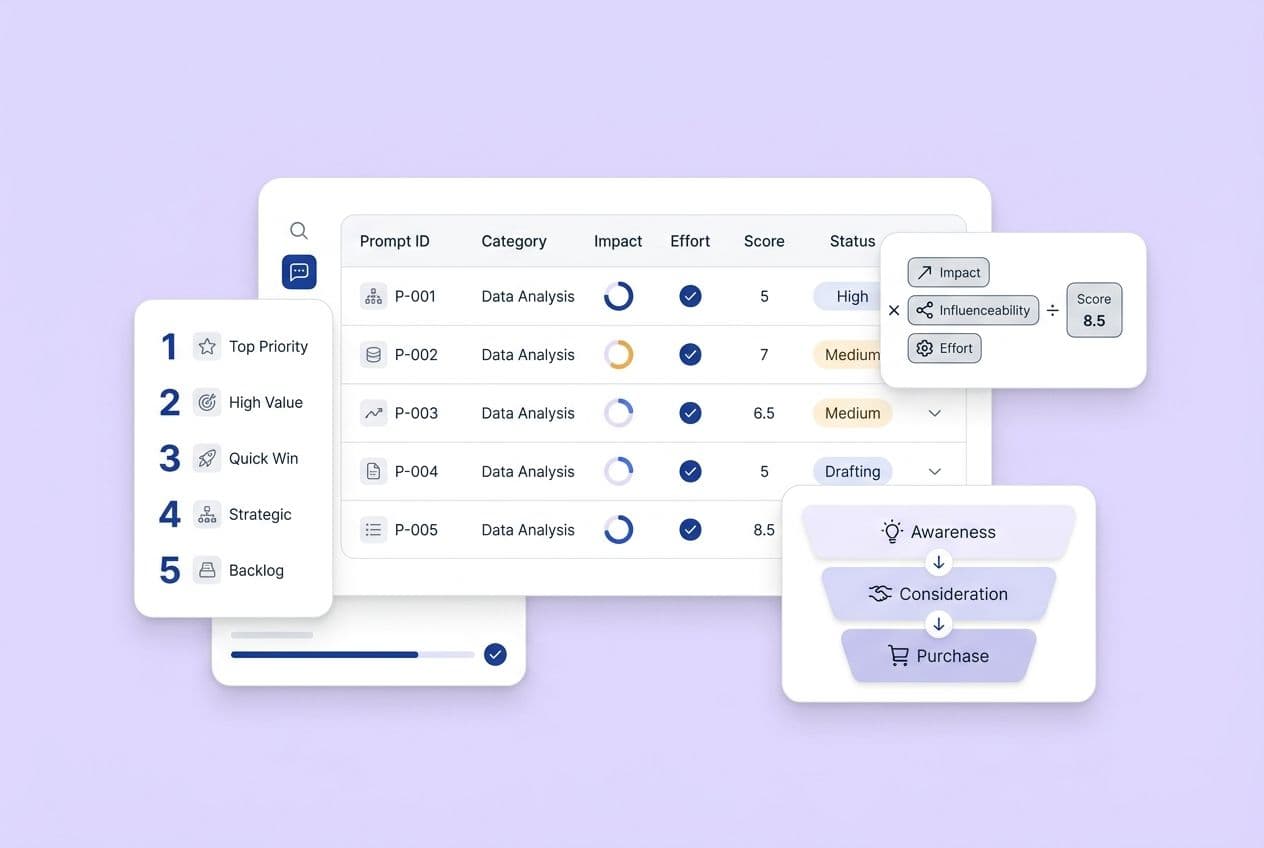
Success here isn't just "more traffic from AI." It's your brand being consistently cited when your ideal buyers ask relevant questions: things like "best tools for SOC 2 compliance," or "how does contract lifecycle management work," or "what's the difference between X and Y." That's the outcome worth tracking.
What Changes in How You Should Write and Structure Sections?
This is probably the biggest shift for most content teams. Each section should open with a 1–2 sentence direct answer before you give any context or qualification. That’s what retrieval systems scan first. If your opening is just vague throat-clearing, the system moves on to a competitor that got straight to the point.
It also helps to use question-style H2 and H3 headings, because they mirror how real buyers phrase their queries to AI platforms. Lists, numbered steps, and comparison tables are much more parsable than dense walls of prose. And please, keep your terminology consistent. Calling the same concept five different things on one page creates entity ambiguity, which makes AI systems less confident in citing you.
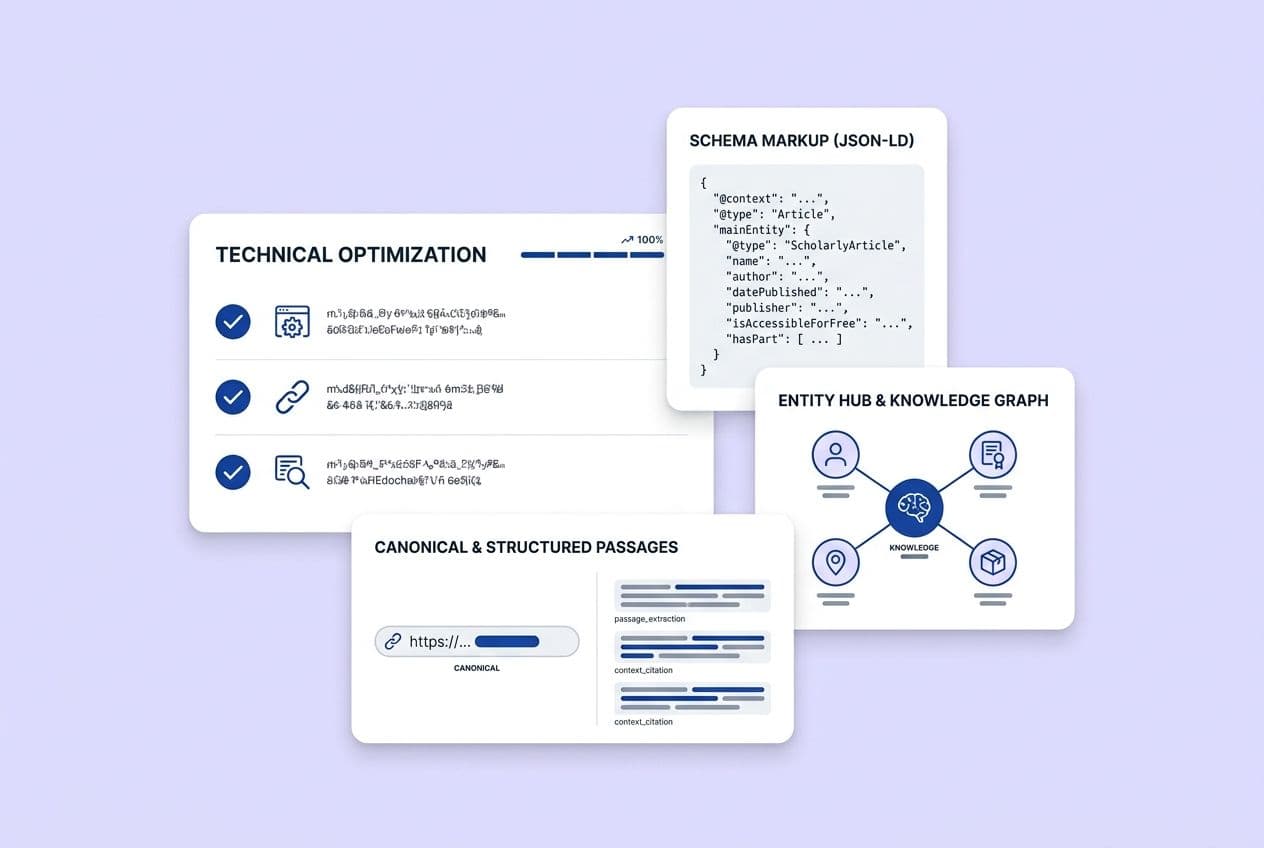
What's the Highest-Impact Schema for LLM Citation (and What Breaks It)?
Schema markup is how you tell retrieval systems who is speaking, what this content is, and how it answers a question. For those of us in SaaS, not all schema types are created equal. Here's where I'd start.
Priority Schema Types for SaaS Content
1. Organization schema: This is foundational. It establishes your brand as a recognized entity with a consistent identity (name, URL, logo, social profiles). Every single page on your site should have this. It's the baseline that makes all your other content more credible.
2. Person schema for authors: This connects the content to a real human with credentials, a role, and an employer. Without this, AI systems can't evaluate an author's expertise. A missing or inconsistent author schema across your blog is a huge gap in your trust signals.
3. Article schema: This covers the headline, author, datePublished, and "dateModified". That dateModified field is critical because retrieval systems use it as a proxy for freshness. If your modified date is stale or just plain wrong, your content looks outdated, even if you updated it last week.
4. FAQ schema: This is for pages with genuine question-and-answer pairs that mirror real buyer questions. Use it where FAQ content actually exists on the page. Don't just stuff it with thin, filler answers. Retrieval systems love well-structured FAQs, but only if the visible content matches what’s in the markup.
5. HowTo schema: Reserve this for truly procedural content that has discrete steps. Don't try to force it onto a conceptual or comparison post. When the schema type doesn't match the content on the page, it just erodes trust.
Schema Best Practices
-
Use JSON-LD in the
<head>. It's the format that crawlers parse most reliably. -
Use absolute URLs for everything. Relative paths are notorious for breaking schema parsing.
-
Apply multiple schema types per page where it makes sense (Article, Organization, and FAQ can all live happily on the same page).
-
Keep your schema synchronized with your on-page content. The dates, author names, and Q&A text must match what a user actually sees on the page.
Failure Modes That Reduce Trust
-
Schema/content mismatch: This is the fastest way to get your content ignored. I've seen it happen dozens of time. The schema says the author is one person, but the byline says another. Or the FAQ schema contains answers that aren't even visible on the page.
-
Thin FAQ answers used everywhere: Spamming FAQ markup across your site with one-sentence non-answers just trains systems to distrust all your structured data.
-
Stale or missing
dateModified: AI systems treat content freshness as a quality signal. An article you updated six months ago that still shows its original publish date looks stale and untrustworthy.
Minimal Schema QA You Can Do in Under an Hour Per Template
Pick your three most-used page templates (maybe your pillar page, blog post, and integration page). For each one:
-
Confirm the author name in the schema matches the on-page byline exactly.
-
Confirm org schema is present and linked to the author (usually via
sameAsormemberOf). -
Spot-check the
dateModifiedagainst your CMS update logs. These drift all the time. -
Confirm the canonical URL in the schema matches the actual canonical tag in the
<head>. -
Verify the visible page contains every Q/A pair and every step referenced in your schema. If the content isn't on the page, get it out of the markup.
Run this audit on your templates, not just individual pages. A fix at the template level scales across your whole site.
How Do You Build Entity Pages That AI Systems Can Disambiguate and Trust?
Entity pages function as canonical hubs. They are the single, authoritative source for what a term means in your world, with all related content pointing back to them consistently.
AI systems work by mapping terms to unique entities. When you write about "contract automation," "contract management software," and "CLM platform" interchangeably across your site, you’re creating a mess. The system can't confidently figure out what you mean or whether you're a credible source on any of those topics.
Entity pages function as canonical hubs. They are the single, authoritative source for what a term means in your world, with all related content pointing back to them consistently.
What Entity Pages Look Like for SaaS
-
Product entity pages: Your core product or a specific module. It needs a clear definition, a stable URL, and consistent naming.
-
Use case entity pages: Think "SOC 2 compliance automation" or "revenue forecasting." These are defined from your unique perspective and linked from all your supporting content.
-
Category entity pages: The broader space you compete in, like "contract lifecycle management" or "headless CMS." These are how you establish category-level authority.
-
Integration entity pages: Things like your "Salesforce integration" or "HubSpot integration" page. These are often underbuilt, which is a missed opportunity since buyers often research specific integration questions in AI tools.
Entity Page Must-Haves
-
Canonical name in the H1 and first sentence, written exactly how you want to be cited.
-
Aliases and synonyms handled in the copy. Acknowledge variations like "sometimes called X" rather than scattering them around as competing primary terms.
-
Clear definition in the first 1–2 sentences. Don't bury the "what this is" in paragraph three.
-
Consistent internal linking from spokes. Every supporting article that covers this topic should link back to the hub using the same anchor text.
Governance Gap Fill
I've seen entity page projects fail over and over because no one actually owns them. You need to define:
-
An entity canon owner (often a content ops or SEO lead) who controls the official name, the list of aliases, and the URL for each entity.
-
A change process. If you rename a product or merge two categories, you need a protocol for updating the hub, redirecting old URLs, and updating anchor text across all the spoke pages.
-
Alias tracking. Regional variants, old product names, and marketing-driven positioning shifts all create divergence. Document them so you can consolidate your authority, not scatter it.
A Simple Entity Hub-and-Spoke Internal Linking Rule (That Avoids Chaos)
One hub per entity. Every spoke article that materially covers that entity links to the hub within the first third of the article, using the canonical anchor text.
And please, stop rotating synonyms in your anchor text for "SEO variety." That practice made sense in a different era of ranking. For entity recognition, consistency beats variety. If your category entity is "contract lifecycle management," use that exact phrase, not "CLM tools," "contract software," and "contract ops platform" interchangeably as link anchors.
Finally, avoid creating parallel hubs. You don't want /features/contract-automation and /product/contract-automation pointing to different pages with similar content. Consolidate them, redirect one, and pick a winner.
An entity canon owner (often a content ops or SEO lead) who controls the official name, the list of aliases, and the URL for each entity.
What Canonical URL Rules Prevent AI Systems from "Competing with Yourself"?
Canonicals aren't just for crawl budget and duplicate content anymore. They're attribution anchors. When an AI system retrieves a passage and needs to cite a source, it attributes it to a URL. If your content exists at three slightly different URLs (like HTTP vs. HTTPS, with a trailing slash vs. without, or with UTM params), that citation gets diluted or just plain confused.
Canonical Rules to Enforce at the CMS/Template Level
-
One preferred protocol and host. Pick either HTTPS with
wwwor without, and enforce it with a 301 redirect at the server level. This isn't something you can just hope for. -
Tracking parameter handling. Your canonical tags must point to the clean URL without any UTM or session parameters. Don't let your analytics tagging create a duplicate content nightmare.
-
Faceted navigation. Filtered and sorted versions of your listing pages should either be canonicalized back to the base page or excluded from indexing entirely.
-
Localization. Use
hreflangcorrectly. You don't want to accidentally set a German page as the canonical for an English page. (Yes, I've seen it happen). -
Pagination. Each page in a series should have a self-referential canonical pointing to that specific page. Avoid the old practice of canonicalizing page 2 back to page 1.
Canonical "Must Be True" Checklist
-
The canonical URL returns a 200 OK status, not a redirect chain or a 404.
-
The canonical target is crawlable and indexable, not blocked by
robots.txt. -
The schema in your
<head>references the canonical URL. A mismatch here is a major red flag for crawlers.
Comparison Table: Canonical Chaos Scenarios and the Fix
This is my go-to cheat sheet for explaining this to dev teams.
| Scenario | What Goes Wrong for AI Retrieval | Canonical Rule | Who Owns the Fix |
|---|---|---|---|
| UTM params indexed (e.g., ?utm_source=email) | Same content at multiple URLs; citation split across variants | Canonical points to clean URL; exclude params in CMS settings | SEO / Dev |
| HTTP and HTTPS both accessible | Duplicate content; retrieval may cite the wrong version | Force HTTPS via 301; canonical always HTTPS | Dev |
| www vs non-www both live | Split signals; attribution fragmented | Pick one, 301 the other, canonical enforces preference | Dev |
| Trailing slash variants (/page vs /page/) | Two indexable URLs for same content | Enforce one pattern at server level; canonical confirms | Dev / SEO |
| Faceted nav creates /category?color=blue&size=m | Hundreds of low-value URLs; entity page authority diluted | Noindex or canonical to base; avoid indexing combinatorial variants | Dev / SEO |
| Duplicate category paths (/blog/category/x + /tag/x) | Competing entity signals; canonical confusion | Consolidate taxonomy or canonical one to the other | Content Ops / SEO |
Canonical drift during site migrations is the most common and painful failure mode. It can affect every template at once and often isn't caught until your AI citations start pointing to dead or redirected URLs. site migrations often require careful redirect mapping and pre-launch validation to avoid this.
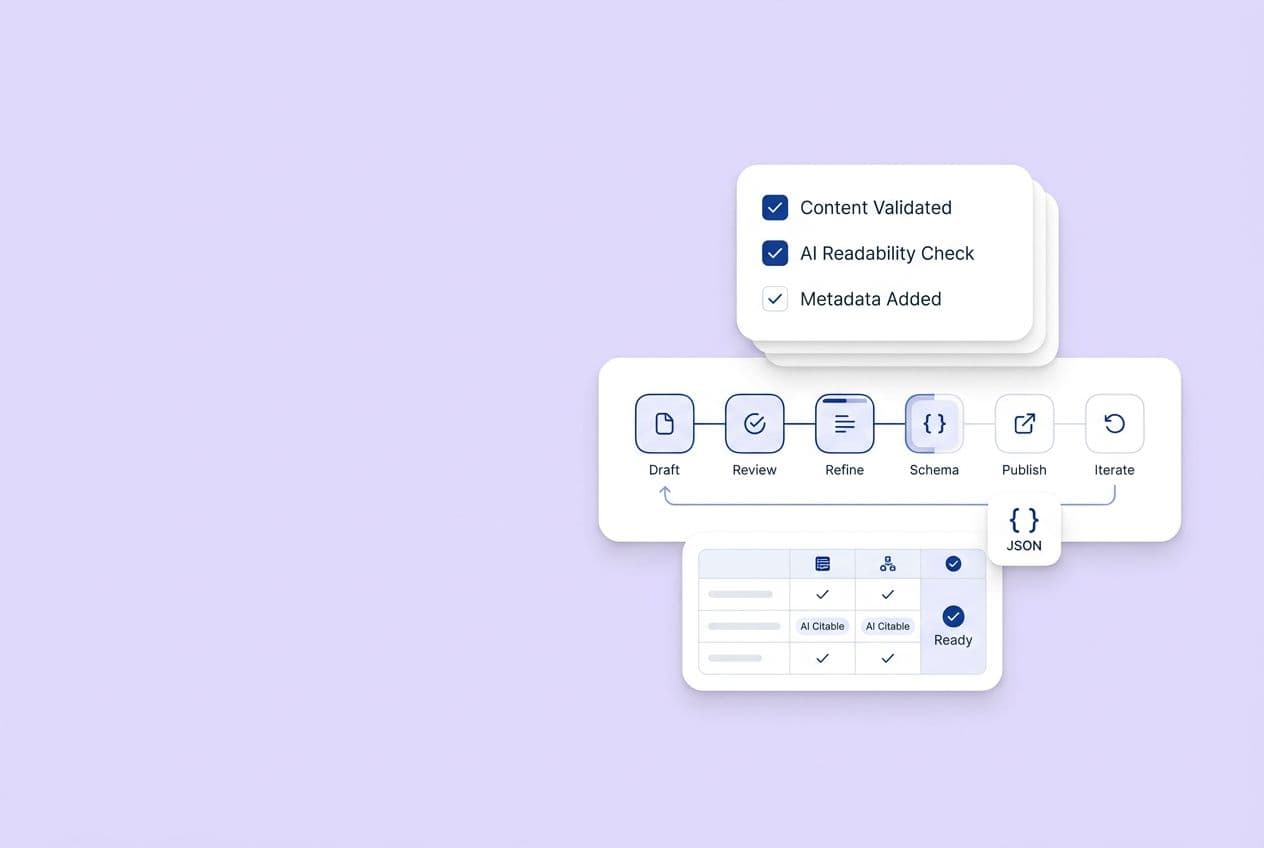
How Should You Structure Content So LLMs Can Retrieve It as Grounded Passages?
Write for extractable claims. This is the single biggest structural shift most SaaS content teams need to make. Every section should open with its answer and then support it, not build up to a grand conclusion at the end.
The Extraction Test
Before you publish any section, apply this quick two-part test. It takes 30 seconds.
-
Read the first two sentences of the section in isolation. Do they directly answer the question in the heading? If someone pulled just those sentences, would they be accurate and useful on their own? If not, rewrite the opening.
-
Read the first 200 words of the page in isolation. Does it work as a standalone summary of what the whole page covers? Your page intro should be the most citable chunk of content on the entire page.
Formatting That Improves Retrievability
-
Short paragraphs (2–4 sentences). Dense walls of text just get skipped.
-
Bulleted lists for non-sequential items and numbered steps for procedures.
-
Tables for comparisons, trade-offs, and option sets. AI engines consistently favor structured tabular content for citations. It's just easier for them to parse.
-
Consistent terminology. Pick your terms and stick with them. If the concept is "semantic chunking," don't call it "content segmentation" two paragraphs later. Synonym rotation creates ambiguity and reduces citation confidence.
Semantic Chunking Guidance for Content Teams
You want to chunk your content by headings, list boundaries, and natural topic shifts, not by some arbitrary word count. Each chunk should ideally carry three elements:
-
What it is: The concept or claim being made.
-
Who it's for: Any role, use case, or condition that scopes the claim.
-
Edge cases or constraints: When it doesn't apply, or what to watch out for.
This isn't about catering to some mysterious vector database architecture. It's just about writing clearly enough that a system (or a person, for that matter) can pull out a discrete, accurate statement from your content without needing all the surrounding context.
Completeness beats depth-only. A page that covers all the expected subtopics for a query, even if it's at a moderate depth, is often a more reliable source than one that goes super deep on one angle and skips the others. AI systems evaluate topical coverage, not just the quality of one section.
What to Do When Your Content Is JS-Heavy or Behind Interactions
If you can, server-render your core content. If the text only appears after a JavaScript execution or a user clicks something, most AI crawlers won't see it. This is a huge problem for content hidden inside tabs, accordions, or "read more" toggles.
Your key content, like definitions, process steps, and claims you want cited, should be in the static HTML from the start. You can use progressive enhancement for the interactive bells and whistles, but don't make the substance dependent on client-side rendering. A simple way to check this is to disable JavaScript in your browser and reload your key pages. What you see is roughly what crawlers see.
What Should You Audit and Monitor to Validate "Citation Readiness" Over Time?
Optimizing for LLM retrieval isn't a one-and-done checklist. The teams I've seen improve their citation rates treat it like any other operational task: a recurring audit, a small set of priority prompts to track, and a feedback loop based on what's actually working.
Technical Validation Checks
-
Bot access audit: Verify that GPTBot, ClaudeBot, PerplexityBot, and Googlebot are allowed in your
robots.txt. Check that no critical assets are blocked. Do this after every significant CMS or infrastructure change. -
Schema validation: Run a quick spot check on your top three templates after any schema change. Use Google's Rich Results Test and just look at the JSON-LD to confirm your schema and content are in sync.
-
Canonical audit after releases: Any site migration, CMS update, or template change can cause canonicals to drift. Run a post-deploy crawl to check for new duplicate URLs or broken canonicals.
Content Validation Checks
-
Section opener review: Pull your 10 highest-priority pages and read only the first two sentences of each H2. Are they direct answers or just scene-setting? Rewrite the ones that don't pass the extraction test.
-
Entity hub inventory: Identify the 5–10 entities most central to your business. Does each one have a hub page? Is it consistently linked from supporting content with the right anchor text?
Iteration Loop
Pick a small set of priority prompts that you know your buyers are asking AI platforms. Monitor whether your pages get cited for them. When a page doesn't get cited, check in this order: access (can the bot reach it?), identifiers (is the canonical clean?), and extraction (does the section opener answer the question directly?).
Adjust the pages most likely to be cited first. Don't try to fix everything at once. A focused sprint on five important pages is much better than a broad, superficial sweep that touches fifty.
Distribution as a Trust Accelerant
AI systems still echo the authority signals of the broader web. Earning genuine backlinks and brand mentions from authoritative sources makes it more likely that retrieval systems will treat your content as a reliable source. This isn't a shortcut; it's the same hard work that improves traditional SEO.
And be honest with yourself about the lag time here. Changes to schema, canonicals, and content structure can take weeks or even months to show up in citation patterns. Audit consistently, iterate based on real signals, and treat citation rate improvement as a durable, compounding investment, not a quarterly sprint with a guaranteed ROI.