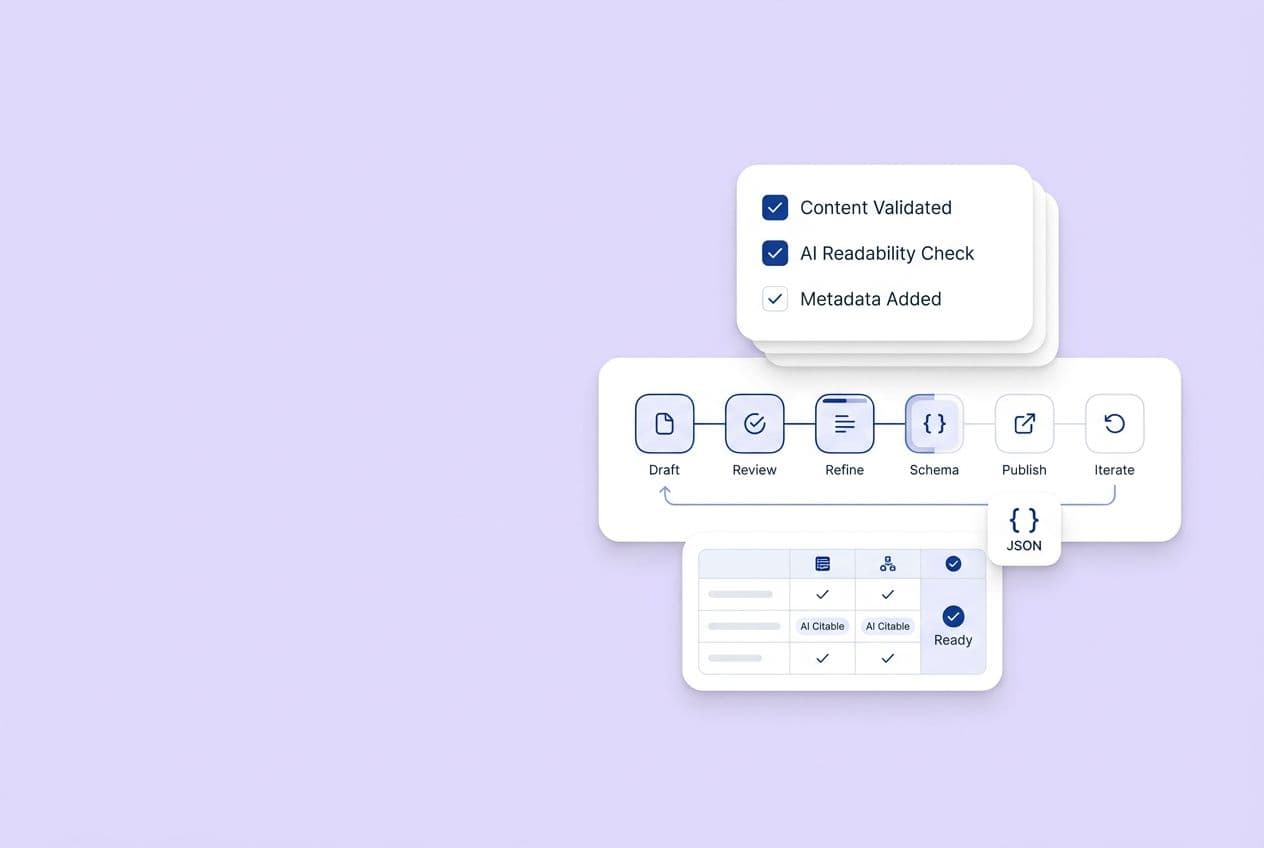
Let’s cut right to the chase. Here is the exact framework: Source prompts → Categorize by intent and buyer stage → Score using Impact × Influenceability ÷ Effort → Prioritize a 20–40 prompt portfolio → Baseline across 2–3 AI platforms for 30+ days → Turn tracking deltas into content actions. That’s it. No magic, just the whole system laid bare. We aren't trying to boil the ocean and track every obscure question a buyer might randomly type. Instead, we’re building a tight, curated portfolio you can actually measure, win, and run like a machine.
But if your world looks anything like mine used to, I know exactly what's happening behind the scenes. Your traditional SEO pipeline is already maxed out. Checking your AI visibility mostly consists of random, panicked spot-checks—usually when someone runs a ChatGPT search, sees a competitor, and fires off a Slack message that quickly dies a lonely death. Meanwhile, leadership is asking for an "AI search strategy" (using that tone implying it was due yesterday), and you’re left without a solid answer. Every time you try to wrangle it into a process, the sheer randomness of the AI makes it feel like you’re trying to measure fog. I’ve been there. It is utterly exhausting.
This playbook is what it actually looks like when you stop relying on heroic, one-off searches and start running a real, repeatable system.
By the time we're done, you'll walk away with the entire engine: a prompt sourcing checklist, a five-part prompt taxonomy, a scoring template that drops right into your spreadsheets, a realistic tracking cadence, an execution loop that translates raw data into actual marketing work, and a one-slide reporting framework you can slide across the table to your CMO with total confidence.
What Does "AI Discovery" Actually Mean for Prompts (and How Is It Different from SEO Keywords)?
Let's be clear about what we’re even talking about. AI discovery is whether your brand gets mentioned, cited, or recommended when a buyer asks a detailed question to an AI. That’s it. It isn't a rank. There is no position #1 you can own. The goal you're chasing is share of conversation, which is a totally different mindset from old-school SEO.
Here's what you actually track for each prompt:
-
Mention: Your brand name shows up in the response.
-
Citation: A specific page from your site is referenced or linked.
-
Recommendation: The AI suggests your product as a solution.
-
Context/Sentiment: Why you were (or weren't) included.
These four outcomes tell you different things. A mention without a citation means the AI knows you exist but doesn't see your content as evidence. A citation without a recommendation means you’re seen as useful background reading, not the winner. You have to track all four.
I need you to burn this into your brain: prompt tracking is directional, not precise. The answers you get will change based on the AI model, the time of day, how you phrase the question, and whatever weird retrieval logic the platform is testing this week. You aren't measuring a fixed position. You're just trying to spot patterns in the chaos.
This is why a prompt isn't just a long keyword. A keyword is "internal linking tool." A prompt is "What's the best internal linking tool for a SaaS team that publishes 8 posts a month and uses WordPress?" The prompt has context, constraints, and criteria, just like a real buyer. That specificity is what makes the answers useful and the prompts worth tracking.
The takeaway is that you need a portfolio of prompts across the entire funnel to see the full picture. Focusing on one type of prompt means you're flying blind.
What Should You Measure Per Prompt (Minimum Viable Metrics)?
Track these five things every time you run a prompt: mention (Y/N), Citation (Y/N + URL), recommendation (Y/N), a one-line context note, and the date/platform. That’s your bare-minimum dataset.
Why not just run it once? Because a single output tells you nothing. One bad result could be a fluke, and one good result might never happen again. You need to see a trend over time before you make a move. Make this your rule: don't act on a single data point. Act on what you see consistently across 3 to 5 runs.
Which Prompt Types Should You Map So You Don't Miss Where Buyers Decide?
A solid prompt map covers five types that connect to specific stages in the buyer's journey. If you skip one, you'll have a massive blind spot. For most B2B SaaS companies, the highest-value prompts are almost always the comparative ones from the consideration stage.
| Prompt Type | Buyer Stage | Example |
|---|---|---|
| Informational | Awareness | "What causes slow content production for a small SaaS team?" |
| Comparative | Consideration | "Best AI content tools for a 3-person marketing team vs hiring an agency" |
| Instructional | Consideration/Purchase | "How do I build an AEO content strategy without adding headcount?" |
| Brand-specific | All stages | "What does [Your Brand] do and who is it for?" |
| Transactional | Purchase | "How do I migrate from Surfer SEO to a new content tool without losing rankings?" |
A few thoughts on this breakdown:
-
Comparative prompts are your bread and butter. This is where buyers are actively weighing their options. Prompts like "best tools for X," "X vs Y," and "alternatives to Z" are a gold mine.
-
Informational prompts build top-of-funnel awareness but won't usually lead to a direct recommendation. They're good for growing your category presence.
-
Brand-specific prompts are a health check. They tell you if you're being described accurately, but they don't grow discovery. Don't waste too much time on them. They show what you have, not what you could win.
-
Transactional prompts about pricing, migration, or security are more important than you'd think in B2B, where buying something is a risky decision. Track them if they mirror real objections your sales team hears.
Remember to add persona modifiers to make prompts real. A prompt without constraints is just a keyword. Add team size, industry, tech stack, or budget to force the AI to make a real recommendation.
Your goal for this raw list should be 50–100 prompts. Don't worry, you'll cut it down in the next step.
A Simple "Prompt Rewrite" Formula to Get from Generic to Trackable
Here are three templates that will turn your messy list into trackable, decision-focused prompts:
-
"What's the best [category] for [persona] who needs [constraint] and cares about [criterion]?"
- Example: "What's the best content production tool for a 2-person SaaS marketing team that cares about brand voice consistency and built-in SEO?"
-
"Compare [Vendor A] vs [Vendor B] for [use case], including [specific criteria]."
- Example: "Compare Jasper vs a multi-agent content platform for a team that needs AEO optimization and competitive citation tracking."
-
"How do I [job-to-be-done] without [common risk or trade-off]?"
- Example: "How do I scale content production to 12 posts a month without sacrificing editorial quality or brand voice?"
Run your raw list through these templates. If you can't shape a prompt into one of them, it’s probably too vague to be useful.
Where Do You Find High-Intent Prompts That Match Buyer Language (Without Guessing)?
Stop guessing. The best prompts are already sitting inside your company, in the places where real buyers told you exactly how they think. Everything else is a weaker signal.
Start with your internal, high-signal sources:
-
Support tickets: This is where you find pain points in your customer's own words, often verbatim. I once found our most valuable prompt buried in a ticket from a furious customer. They were complaining, but they also dropped a perfect "we almost chose [Competitor] because..." sentence that became our north star.
-
Sales call transcripts: Listen for objections, comparisons, and decision criteria. Any time you hear "we're also looking at X," you've found a prompt.
-
Demo requests and churn notes: Look at what made someone choose you or, just as importantly, what made them leave.
-
Onboarding questions: These are perfect for finding instructional prompts about implementation.
These sources are gold. The language isn't cleaned up for SEO or sanitized by marketing. It's raw, real, and exactly how a frustrated human talks to a machine to get a real answer.
Then, expand your list with external sources:
-
Google Search Console long-tail queries: Ignore the head terms. Dig for the 6 to 10-word questions that sound like a real person talking.
-
"People Also Ask" patterns: Look at the structure of the questions, not just the exact phrasing.
-
Reddit, Quora, and community forums: Find the conversational questions you'd never see in a keyword tool.
-
Competitor positioning pages: See what comparison angles they're hitting.
-
AI-suggested follow-ups: After running a core prompt, ask the AI what related questions people ask. Use these for ideas, not as confirmed signals.
Refinement rule: Turn every vague topic into a specific prompt. "AI content tools" isn't a prompt. "What's the best AI content tool for a content lead at a Series B SaaS company with two writers?" is a prompt. Constraints transform keywords into decision questions.
Your goal for this raw list should be 50–100 prompts. Don't worry, you'll cut it down in the next step.
A Simple "Prompt Rewrite" Formula to Get from Generic to Trackable
Here are three templates that will turn your messy list into trackable, decision-focused prompts:
-
"What's the best [category] for [persona] who needs [constraint] and cares about [criterion]?"
- Example: "What's the best content production tool for a 2-person SaaS marketing team that cares about brand voice consistency and built-in SEO?"
-
"Compare [Vendor A] vs [Vendor B] for [use case], including [specific criteria]."
- Example: "Compare Jasper vs a multi-agent content platform for a team that needs AEO optimization and competitive citation tracking."
-
"How do I [job-to-be-done] without [common risk or trade-off]?"
- Example: "How do I scale content production to 12 posts a month without sacrificing editorial quality or brand voice?"
Run your raw list through these templates. If you can't shape a prompt into one of them, it’s probably too vague to be useful.
How Do You Filter Prompts Down to a Winnable Set Before You Score Them?
Don't try to score all 80 prompts. You’ll burn hours on things that don’t matter. Filter your list through these four gates first. If a prompt fails any of them, cut it.
Gate 1 — Competitive relevance: Would your brand or a direct competitor realistically show up in the answer? If not, it's probably too generic. Cut it.
Gate 2 — Influenceability: Are the results dominated by sources you can't beat? If every citation is from Wikipedia or a major news outlet, you're not going to win. If every citation is from Wikipedia, you're not going to win a spot.
Gate 3 — Business intent alignment: Does this prompt connect to a real pain point for your ideal customer? Tracking "cool" prompts that aren't tied to buyer decisions is a vanity project.
Gate 4 — Specificity: Is the prompt still too broad even after you tried rewriting it? It might need to be split into two prompts, or just thrown out.
After filtering, you should have a shortlist of 25–60 prompts ready for scoring.
Red Flags That a Prompt Will Waste Your Month
Be on the lookout for these time-wasters during the filtering process:
-
Too broad: "What is content marketing?" No one uses this to make a buying decision.
-
No buyer intent: "Fun ways to brainstorm blog ideas." This is for curiosity, not vendor evaluation.
-
Impossible authority wall: Every citation is a university, a government body, or a tier-1 publication. You're not breaking through that wall.
-
No credible page to create: If you can't imagine what content you would even create to answer the prompt, skip it.
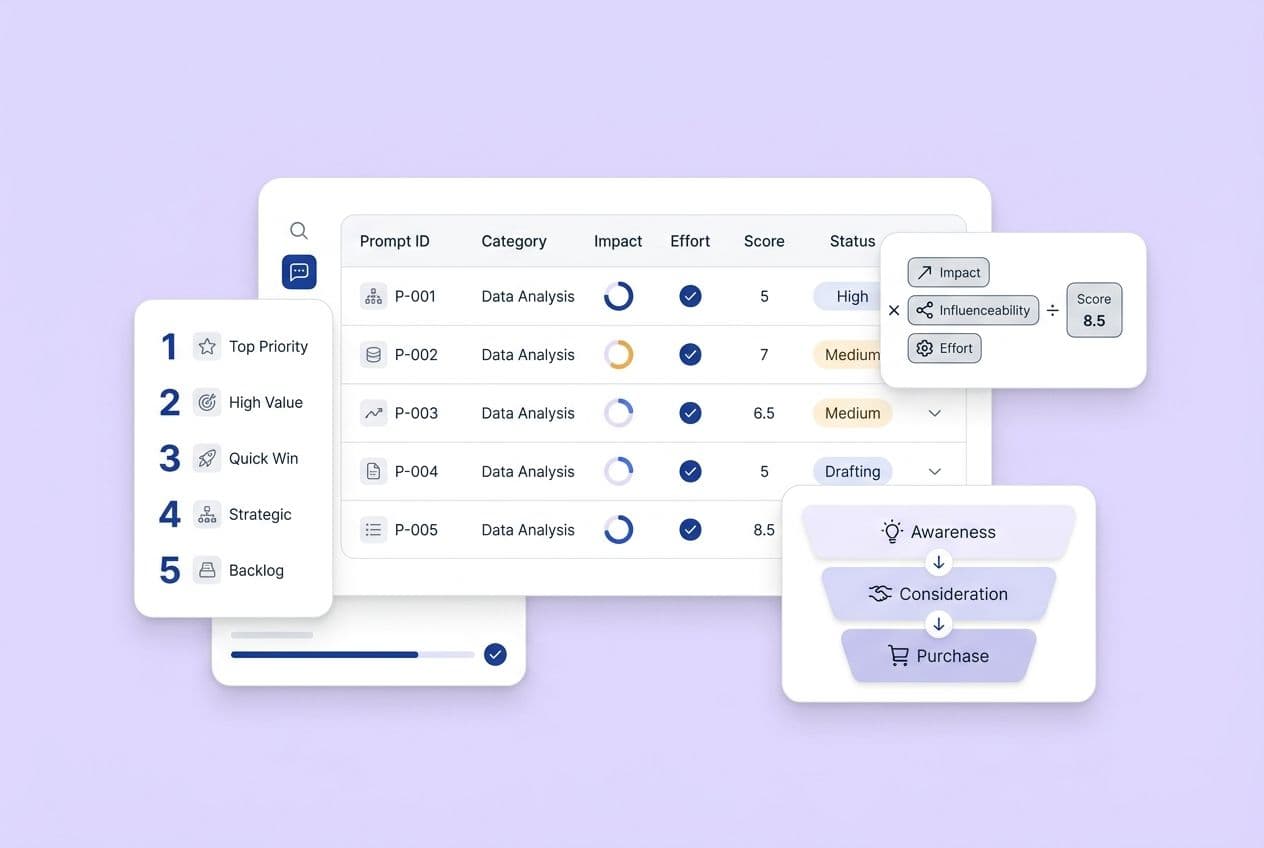
What Scoring Model Should You Use to Prioritize Prompts (With a Spreadsheet-Ready Template)?
If you can't explain why you chose Prompt A over Prompt B in 30 seconds, your whole system will fall apart the first time a stakeholder questions it. And they will. This scoring model isn't about being perfect; it's about being defensible. That’s the entire point.
Score each of your shortlisted prompts from 1 to 5 on these columns:
| Column | What It Measures | Scoring Note |
|---|---|---|
| Business Impact | Proximity to pipeline, ICP fit, deal size | 5 = maps directly to a high-value buyer decision |
| Reach/Prevalence | How often this question appears (use search data or sales call frequency as a proxy) | This is directional, so just make your best guess |
| Influenceability | Likelihood you can earn a citation with better content | 5 = winnable with a great article; 1 = institutional lock-in |
| Competitive Gap | Competitors appear in responses where you don't | 5 = they're always there, and you're not |
| Effort | New content vs. a refresh; need for data, design, etc. | 5 = hardest (you'll invert this in the formula) |
| Confidence (optional) | How sure you are about your other scores | A good tie-breaker when data is thin |
Pick one formula and stick with it:
-
Simple version:
(Impact + Influenceability + CompetitiveGap) − Effort -
Stronger version:
(Impact × Influenceability × CompetitiveGap) ÷ Effort(just normalize the scales first) -
RICE-style variant:
(Reach × Impact × Confidence) ÷ Effort(product teams will recognize this, making it easier to explain)
Here's a quick example with 3 prompts:
| Prompt | Impact | Influenceability | Comp. Gap | Effort | Score (Simple) |
|---|---|---|---|---|---|
| "Best AI content tools for lean SaaS teams" | 5 | 4 | 5 | 2 | 12 |
| "How to build an AEO strategy without headcount" | 4 | 3 | 4 | 3 | 8 |
| "What is answer engine optimization?" | 2 | 2 | 2 | 1 | 5 |
The first prompt is the clear winner. It has high business relevance, a real competitive gap, and is relatively low effort. The last one is easy to create content for, but the business impact is low. It's not going to move a buyer toward a decision.
Your goal is to pick the top 20–40 prompts for your active portfolio. This is the set you will track, execute against, and report on.
The Priority Matrix View (Impact vs. Effort) You Can Use in Stakeholder Meetings
This simple 2x2 grid ends arguments before they start and requires zero spreadsheet explanation.
-
High impact / low effort → Do now. These are your quick wins. Refresh a page, tighten a heading, add a direct answer.
-
High impact / high effort → Plan and resource. These are your big projects, like original research or new comparison pages. They need a timeline and an owner.
-
Low impact / low effort → Backlog fillers. Do these when you have a slow week. Don't let them jump the queue.
-
Low impact / high effort → Avoid. Just stop. If it’s expensive and doesn't help a buyer, it's not a content investment, it's a content tax.
The matrix forces a productive conversation. When a stakeholder insists a prompt is important, you can ask, "Okay, where does it fit on the impact/effort matrix?"
The "Board-Ready" Story: 3 KPIs to Report Monthly
Keep your executive updates simple. Focus on three numbers:
-
Portfolio mention rate trend: What percentage of your tracked prompts mentioned our brand this month versus last month?
-
Portfolio citation rate trend: What percentage cited a page on our domain?
-
Competitive share: On our tracked prompts, how often are competitors cited versus us?
These are leading indicators, not revenue attribution. Be upfront about that. It builds trust. Tools like DeepSmith's AI Visibility Overview can dashboard these for you, which saves a ton of manual work every month once your prompt set is stable.
How Should You Baseline and Track Prompts When AI Answers Change Every Day?
To reduce the noise, you have to commit to a stable prompt set, consistent platforms, and a 30-day minimum baseline before you make any decisions. One-off results are meaningless. You need a pattern over 30 days or more.
Here’s the recommended scope for tracking:
-
20–40 prompts from your priority list.
-
2–3 AI platforms. Pick the ones your buyers actually use and stick with them. Adding a new platform mid-cycle will corrupt your data.
-
30+ days for your initial baseline. You'll need 60-90 days to spot real trends.
Log this for every run (this is your minimum viable dataset):
-
Prompt text (and any modifiers you used)
-
Platform and model version
-
Citation (Y/N + URL)
-
The URL(s) cited
-
A one-line note on the context
Follow this cadence:
-
Weekly review: Note any big changes, but don't react yet.
-
Monthly decision-making: Look for patterns and update your content plan.
-
Every 30–60 days: Review your prompt list. Buyer language and priorities change.
A quick note on citation drift: AI platforms change how they cite things all the time. If a prompt that always cited you suddenly stops, it might not be your content's fault. Look for consistent patterns. One bad day is noise. Four straight weeks of a declining citation rate is a signal.
Trying to do this manually gets messy fast. Running 30 prompts on three platforms every week is a recipe for spreadsheet hell. A platform like DeepSmith can track this automatically across ChatGPT, Gemini, Perplexity, and more, so your data stays clean.
How to Handle Prompt Variants Without Corrupting Your Data
Track a canonical prompt and log any variations as children of that parent prompt. Only change one thing at a time, like the industry or team size, so you can see what actually affects the response.
Decide ahead of time what counts as a "prompt family" for reporting. If you're tracking "best AI content tool for a 50-person SaaS team" and also test "best AI content tool for a Series B SaaS company," those are variants. You should either report on them together or be clear about why they're separate.
How Do You Turn Prompt Priorities Into a Content Plan Your Team Can Actually Execute?
If your prioritized prompts don't map to a specific content action with an owner, you're not running a program. You're just running a monitoring dashboard that no one looks at.
Here's how to map prompts to actions:
| Prompt Type | Content Action | AI-Citable Checklist |
|---|---|---|
| Comparative | Comparison page, alternatives page | Lead with a direct verdict; use a structured table for criteria. |
| Instructional | How-to guide, SOP, checklist | Start with the direct answer; use numbered steps and clear headers. |
| Informational | Category primer, glossary | Define the term in the first sentence; use bullet points for criteria. |
| Brand-specific | Product pages, FAQs, support docs | Ensure claims are accurate; use a Q&A format and internal links. |
The "AI-citable section" checklist for every piece of content you update:
-
Open with a direct, 1 to 2-sentence answer. Don't bury the lede.
-
Use structured lists and tables for comparisons and criteria.
-
Use the prompt's phrasing in a heading.
-
Add or strengthen internal links to supporting pages.
-
Tighten the prose. AI engines prefer clarity over fluff.
Build a monthly execution queue your team can actually manage:
-
Aim for 3–5 content actions per month for a small team. Refreshes count and often have a bigger impact than new content.
-
Mix refreshes with new content. Don't create a queue of five brand-new posts and then wonder why you're already behind.
-
Assign an owner and a due date to every item.
The bottleneck isn't usually knowing what to write. It's the gap between saying "we should update this" and getting a brief into a writer's hands. An integrated tool like DeepSmith can turn priorities into production-ready outputs (research, briefs, draft structure), letting your team focus on judgment, not assembly. But you still need humans for the strategic thinking and editorial review.
A Simple Workflow: From Tracking Result → Content Action
You'll see these three scenarios over and over:
-
You're mentioned but not cited. The AI knows you exist but doesn't trust your content as evidence. Audit the relevant page. Is there a clear, direct answer? Is it scannable? Are there internal links? Fix it and check the prompt again in two weeks.
-
A competitor is cited for your target prompt. Don't just make a note of it. Go look at their page. What did they do that you didn't? A table? A better definition? A clearer comparison? Build something better and more structured. DeepSmith's Competitors feature can show you which competitor pages are winning citations so you're not hunting for gaps manually.
-
Nobody is consistently cited. Don't chase a citation that isn't happening yet. Just focus on creating the clearest, most direct answer for that prompt. Build the page you wish existed. Then track it for the next 60 days to see if a trend emerges.
How Do You Socialize Prompt Priorities and Results Internally (Without Sounding Like It's All Vibes)?
Frame your work as a system: portfolio + cadence + KPIs. This isn't a monitoring report; it's a strategic program. A report is passive. A program connects your actions to goals and resources.
Here's the story for leadership:
-
Why this matters: High-intent buyers are using detailed prompts to make decisions before they ever talk to sales. These are not casual searches.
-
What we're doing: We're managing a scored portfolio of prompts of 20–40 prompts, tracking them weekly, and running a monthly content execution loop based on the results.
-
What we're not claiming: We can't promise perfect measurement or direct revenue attribution yet. We're building leading indicators that show traction before it appears in the pipeline.
Show this one slide every month:
-
Your prompt portfolio size and any changes.
-
A 3-month trend line for your mention rate.
-
A 3-month trend line for your citation rate.
-
Top 5 wins this month and the content action that drove them.
-
Top 5 gaps (where competitors are winning) and your plan to fix them.
How to ask for resources:
When a high-impact prompt has a high effort score because it needs original research, you now have the data to back up your request. "This prompt maps to our top ICP, a competitor owns the conversation, and we can't win without a data piece. I need 4 hours from the product team to help me." That's a real, defensible ask, not a vague content request.
Leadership wants to know where you're losing to competitors and what you're doing about it. Competitive citation tracking gives you that story. When you can say, "Competitor X is cited in 70% of our comparison prompts, and we're only cited in 20%," the problem is clear, and your content queue is the solution.