Getting AI-citable content at scale isn't magic. It's a system. A checklist-driven one built on five foundations: an answer-first structure that LLMs can grab cleanly, unique credibility signals that earn trust, technical checks so crawlers can find you, distribution loops that build momentum, and clear ownership so it doesn’t just die as “someone’s side project.” That’s the whole model. The rest of this article is the operational detail.
You're already the bottleneck. I get it. You're writing briefs, editing drafts for SEO, doing internal linking by hand, and now leadership is asking about AI search visibility. It feels like just one more thing on the pile. The common response is to treat AI citations like an SEO checklist add-on: tweak a few headings, add a FAQ, and hope for the best. I’ve seen that movie before. That approach produces occasional wins, but it creates no compounding value.
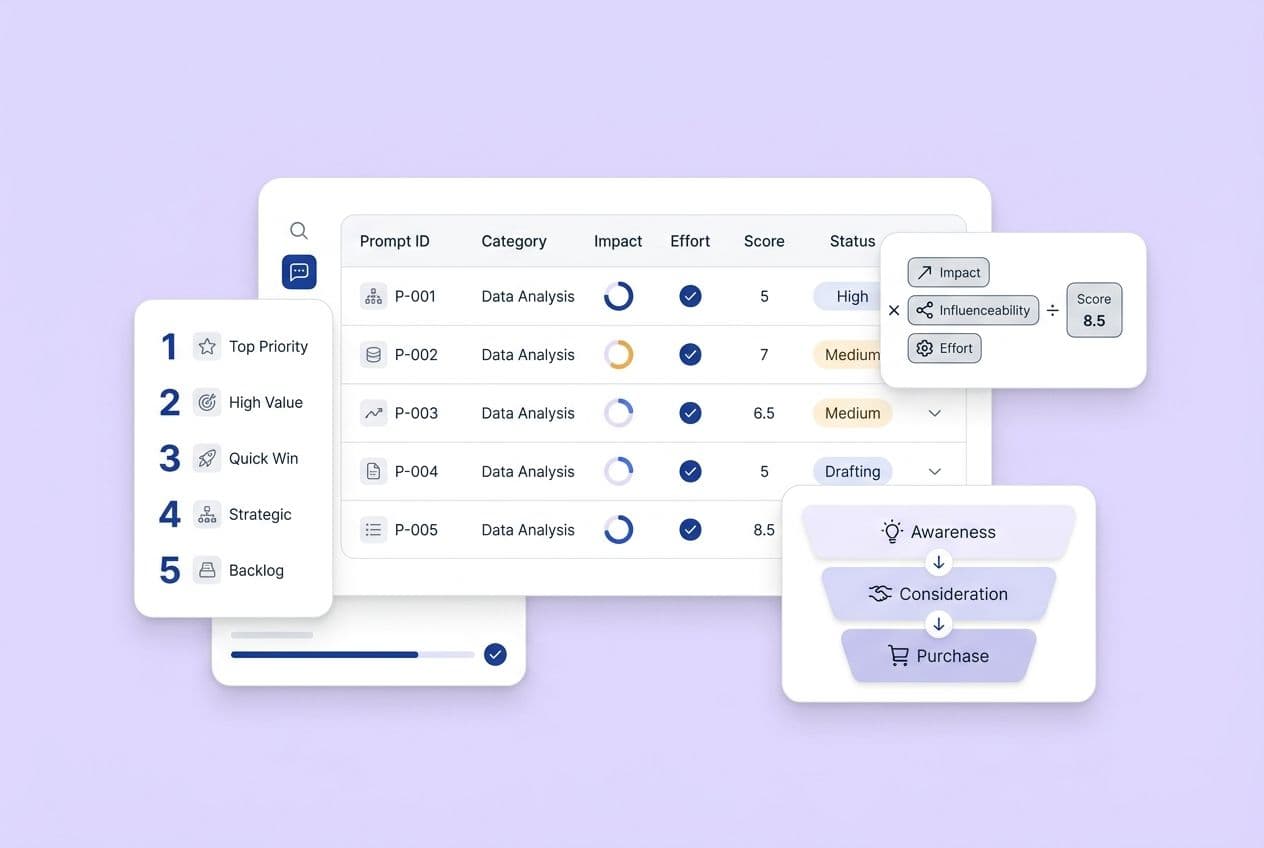
So, I’m giving you the system we use. It’s a series of six checklist gates your content must pass before it ships, plus the technical requirements, scaling guardrails, distribution loop, measurement framework, and role map to run it. Use it to audit your current workflow this week.
What Does "AI‑Citable Content" Actually Mean (and What Does It Not Mean)?
AI-citable content is content that's easy to extract, trust, and attribute. When ChatGPT or Perplexity responds to a query, it pulls from pages that answer cleanly, appear credible, and are structurally easy to parse. The citation isn’t a reward for using AI to write the content or for hitting a word count; it's a byproduct of getting those three things right.
Let’s get one thing straight: cited, mentioned, and ranked are not the same thing. A ranked page appears in traditional search results. A mentioned brand gets named in an AI response without a source link. A cited page gets linked as the source for a specific answer. Mentions are easier to get, but citations are what carry authority.
Why do AI engines cite pages? They need quotable blocks, which are short, self-contained passages that answer a query cleanly. They also need that answer to come from a source that seems reliable, based on signals like author credentials, external links, schema markup, and how fresh the content is.
What AI-citable content is not:
-
Adding a FAQ section and calling it a day.
-
Publishing more AI-generated content (volume without quality just makes things worse).
-
Assuming your SEO rankings automatically translate to AI citations. They don’t map 1:1.
The checklist in this article follows a five-part eligibility model:
-
Eligibility: Can AI crawlers access the page?
-
Extractability: Can they quote it cleanly?
-
Authority: Do signals suggest they should trust it?
-
Recency: Is it current enough to surface confidently?
-
Feedback loop: Does it improve based on what's working?
What Kinds of Pages Get Cited Most Often (and Why That Matters for SaaS)?
Queries that happen late in the buying process like "best [category] tools," "how does X compare to Y," or "[tool] alternatives" tend to trigger list and comparison-style answers. For informational queries, deep how-to guides still win. Both content types get cited, but for different kinds of questions.
Here’s the practical takeaway: your checklist needs to work for both long-form guides and structured comparison blocks. A simple table summarizing trade-offs will often earn a citation where five paragraphs of prose won't. You have to build for both formats instead of defaulting to just one.
What's the Decision-Ready Checklist (the 6 Gates Every Article Must Pass)?
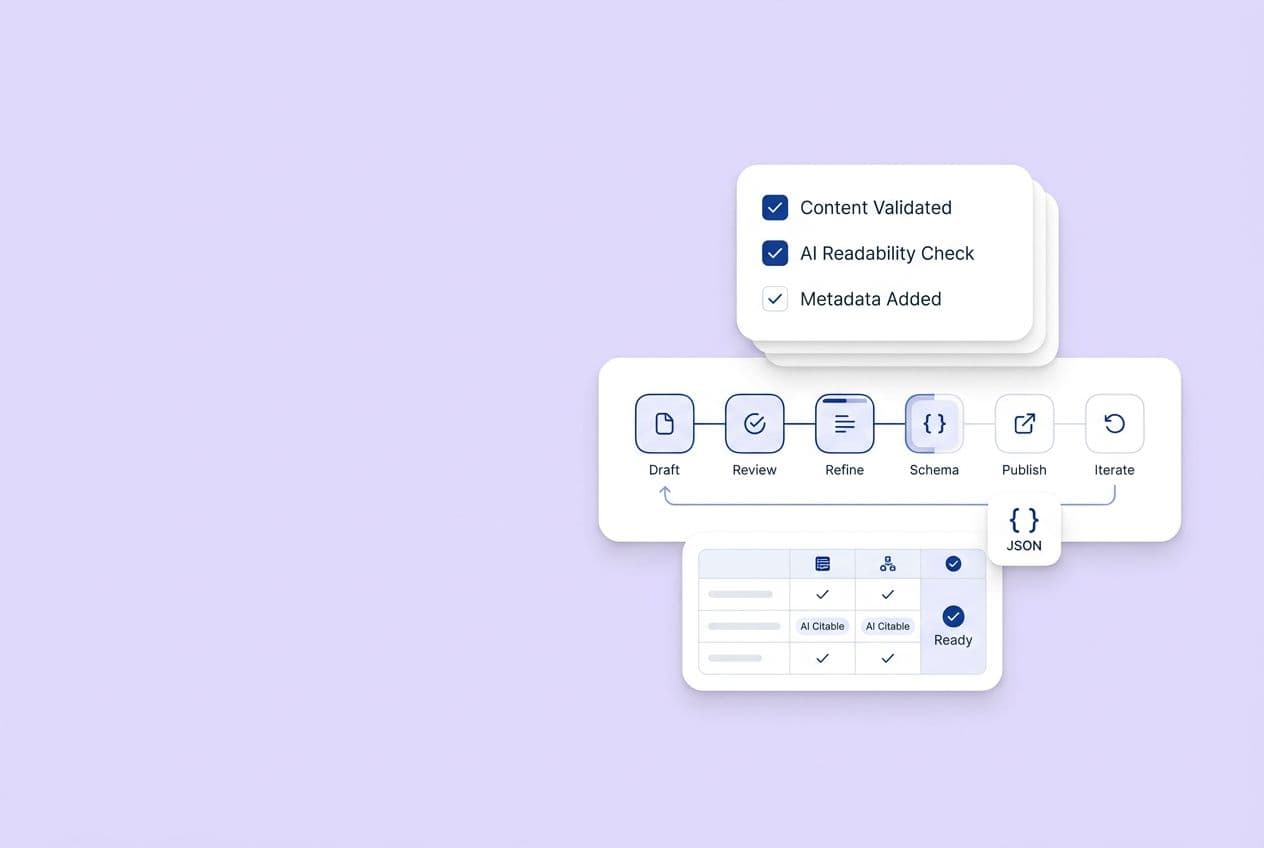
Turn citation readiness into a gated workflow. If a draft can't pass all six gates, it doesn't ship. Simple as that. This turns AI visibility from a periodic audit you never get to into a production standard.
Here are the six gates with their pass criteria:
-
Intent lock: The article targets one query cluster and one audience decision. Pass: You can state in one sentence what a buyer will decide after reading this.
-
Answer-first structure: Every H2 section opens with a direct, quotable answer in 1–2 sentences. Pass: You can pull any section opener and it stands alone without context.
-
Extraction formatting: Claims are broken into atomic paragraphs (2–4 sentences, one idea each), comparisons use tables, and steps use numbered lists. Pass: There are no giant walls of text; each unit is independently parsable.
-
Credibility and uniqueness: The content includes at least one piece of original evidence (like a data point, process artifact, or named framework) and states its limitations. Pass: There's something here that isn't on page one of Google.
-
Technical eligibility: AI crawlers can access the page, schema is present and appropriate, and metadata is aligned with the query intent. Pass: No accidental disallow rules, schema is validated, and the canonical tag is correct.
-
Post-publish loop: The distribution plan is set (Day 0–14 actions), monitoring prompts are defined, and a 30-day update trigger is scheduled. Pass: Someone owns the update decision, and it's on their calendar.
Minimum viable rule: Look, if you're under-resourced and can only execute three gates well, prioritize Gate 2 (structure), Gate 4 (authority), and Gate 6 (iteration). Structure makes you extractable. Authority makes you trustworthy. Iteration keeps you visible.
What to Print or Paste into Your Content SOP
I want this to be practical, so here's a checklist your team can copy directly into every Asana task or Notion brief:
-
Gate 1: Intent locked — query cluster + audience decision documented
-
Gate 2: Every H2 opens with a quotable answer block
-
Gate 3: Extraction formatting applied — paragraphs, lists, tables
-
Gate 4: Unique evidence added; limitations stated
-
Gate 5: Technical pass — crawl, schema, metadata
-
Gate 6: Post-publish loop owner assigned
Assign a primary owner for each gate. In our team, the writer owns Gates 1–4, the SEO specialist owns Gate 5, and the content lead owns Gate 6. I’ll get more into roles at the end of the article.
How Do You Write Sections So an LLM Can Quote Them Without Mangling Your Meaning?
Write in self-contained answer blocks. This means a direct opening answer, one idea per paragraph, explicit definitions, and using structured lists only when a list is truly needed. That's the whole pattern. The rest is just applying it.
Section opening rule: The first one or two sentences of every H2 section should fully answer the heading's question. Don't tease it, just answer it. Expansions, examples, and nuance come after the direct answer.
Atomic paragraphing: Keep paragraphs to 2–4 sentences with one core claim. Multi-idea paragraphs are where meaning gets lost when an AI extracts content. The model might quote part of your paragraph but strip the qualifier that made your claim accurate.
"Contradiction-free" writing: State your answer directly, then add the conditions. I see this mistake all the time.
-
Wrong order: "In some cases, depending on your tech stack, you might consider FAQ schema, though it's not always applicable."
-
Right order: "Add FAQ schema to any section with question-and-answer formatting. The exception is if your CMS strips JSON-LD on publish; work with your web team before adding it."
Query-shaped headings: Match how your buyers actually ask questions. "How do I track AI citations?" will outperform "Citation Tracking" every single time, both for AI retrieval and for human readers.
Bullets vs. numbered steps vs. tables:
-
Use bullets for non-sequential items (like features, considerations, or examples).
-
Use numbered steps only when the sequence actually matters.
-
Use tables for comparisons, specs, or criteria with consistent variables.
"Quotable insight" guidance: In every article, craft two or three sentences that can be lifted verbatim. These should be direct, specific, and require no surrounding context to make sense. Think of them as pull quotes that an AI would actually want to pull.
What to Include in Every "How-To" Section Opening
Every how-to section opener should include three things:
-
A concrete output: What the reader will have when this step is done ("You'll end with a gated checklist your team can paste into every brief").
-
Conditions: When this applies and when it doesn't ("works best when you have a consistent editorial workflow; less useful for one-off content sprints").
-
The first decision point or action: Get straight to the actual step, not the background.
This pattern makes each section independently readable, which is exactly what AI engines need to cite them cleanly.
When Tables Outperform Prose (and What to Put in Them)
Use tables when you're comparing options, evaluating trade-offs, or presenting criteria with consistent variables. Prose buries the comparison; tables surface it. I’ve seen this work firsthand: we had an article that wouldn't get cited, so we turned three paragraphs into a comparison table. Two weeks later, Perplexity was quoting it.
Useful table types for SaaS content teams:
| Table Type | Best For |
|---|---|
| Approach vs. trade-offs | Showing multiple paths with honest downsides |
| Checklist gate vs. pass criteria vs. owner | SOPs and process documentation |
| Metric vs. definition vs. how to measure | Reporting frameworks |
| Schema type vs. use case | Technical eligibility guides |
Keep your columns consistent. Don't add a column to row four that doesn't apply to the first three rows. And define any term in the table that a reader might interpret differently.
What Credibility Signals Actually Increase Citation Likelihood (and How Do You Create Them Without a Research Team)?
Citations follow trust, and trust follows originality. Your fastest path to credibility is creating lightweight original evidence. You don't need a massive research budget for this. AI tools prefer primary or unique information over content that just recombines what's already on page one.
Low-lift original research options for lean teams:
-
Pull anonymized internal aggregates: counts, medians, or time-to-value figures with a defined time window ("across our accounts in Q1, the median time to first published draft was 4 days").
-
Run a mini-survey. Even 20–50 responses from your existing community can be powerful if you note the methodology clearly ("n=34, B2B SaaS content leads, surveyed March 2025").
-
Publish your own content audit stats: the percentage of your pages missing internal links, update frequency by category, or coverage gaps by query cluster.
Quantify everything you can. "Teams often skip internal linking" is a generic statement. "Internal linking is skipped in roughly 60% of drafts when it's done manually post-publish" is citable. Just add a number and a timeframe.
E-E-A-T as actions, not principles:
-
Add author credentials that are relevant to the specific topic. Don't just include a generic bio; add a line that says why this person knows about this subject.
-
Reference recognized frameworks by name (Jobs-to-Be-Done, MECE, RACI) instead of paraphrasing them anonymously.
-
Link out to reputable third-party sources where a claim benefits from external validation.
Lightweight third-party validation: This can be as simple as getting a guest quote from a practitioner (2–3 sentences, attributed clearly), co-authoring data with a partner, or creating mention-earning formats like original research that others will want to cite.
State your limits explicitly. "This works best for teams publishing 4+ articles per month. Lower-volume teams may not see a citation lift from freshness signals alone." This kind of honesty feels counterintuitive, but it reads as expertise, not weakness.
The "Unique Value" Test Before You Publish
Before you hit publish, ask three questions:
-
"What's here that isn't on page one already?" If you can't answer this, the article is probably just adding to the noise.
-
"What would a buyer screenshot?" This helps you find your most useful, specific, and shareable claims.
-
"What would an AI quote verbatim?" This identifies your strongest, most extractable answer blocks.
If the answers to all three are weak, add one concrete element before publishing: a data point, a comparison table, or a documented process artifact. That single addition often makes the difference.
What Technical and Schema Requirements Make You Citation-Eligible (Before Content Quality Even Matters)?
Okay, let's talk tech. If AI crawlers can't access, parse, or understand your page, all this great content work is for nothing. Technical eligibility is the absolute floor. Run this pass before you even worry about answer-first writing.
Crawl and access basics:
-
Check that AI bots (like OAI-SearchBot, PerplexityBot, and GoogleBot) aren't accidentally blocked in your
robots.txtfile. A misplaceddisallowrule on/blog/can kill your eligibility instantly. -
Remove login gates and paywalls from any content you want to be cited. Gated content doesn't get indexed or cited.
Metadata hygiene:
-
Titles and meta descriptions should be natural and descriptive, aligned with what the user is searching for, not just stuffed with keywords.
-
A title like "How SaaS Teams Track AI Citations (A Practical Guide)" outperforms "AI Citation Tracking | SaaS Content | Blog" every time.
Schema by page type:
| Schema Type | Use When |
|---|---|
| Article | Standard blog posts and guides |
| FAQPage | Pages with explicit Q&A sections |
| HowTo | True step-by-step processes with defined steps |
| Product | Product or landing pages (don't force this onto blog posts) |
Emerging: llms.txt: This is a lightweight file you can add to your domain's root to specify how AI systems should interpret your content. It’s still early and not universally supported, but it’s worth asking your web team about if they can implement it in under an hour.
Accessibility and clean HTML: Use heading tags in a logical order (H1 → H2 → H3). Avoid rendering key content only through JavaScript, where parsers might miss it. If your core answer is inside a React component that doesn't render on the server side, it may not be accessible to crawlers at all.
Coordinate with your web or engineering lead on this. SEO specialists should own the schema strategy, while the web team owns the technical execution.
The 10-Minute "Eligibility Audit" You Can Run on Any Post
Run this on your highest-priority pages first. I do this myself.
-
View-source: Is the body content readable in raw HTML (not just rendered)?
-
Schema present: Validate with Google's Rich Results Test.
-
Page loads cleanly: No 5xx errors, no redirect chains.
-
Canonical tag correct: Points to itself (or the intended canonical).
-
Bots allowed: Confirm OAI-SearchBot and PerplexityBot aren't blocked.
-
FAQ markup valid: If you have FAQPage schema, test it.
-
Heading structure: H1 present, H2s in logical order, no skipped levels.
How Do You Scale AI‑Citable Publishing Without Creating Generic, Homogenous Content?
Scale comes from standardizing the right things while protecting the things that create differentiation. The mistake I made early on was trying to automate everything. You end up with high-volume, low-trust content that AI engines have no incentive to cite.
Scalable components (systematize these):
-
Research collection and topic clustering
-
Formatting, internal linking, and metadata
-
Publishing steps and your CMS workflow
-
Distribution asset generation (more on this next)
Must stay human-led (protect these):
-
Your editorial stance and argument
-
What to exclude and what risks to call out
-
Factual verification and product claim accuracy
-
The final voice and tone judgment
Build your "brief → draft → QA" flow with explicit claim boundaries documented. Know what your brand will and won't assert, which statistics are approved for use, and which product capabilities can be named. Without this, volume just creates drift.
Guardrails against AI sameness:
-
Require a point-of-view statement in every intro ("Our position: X is true because Y, and teams that ignore Z will find...").
-
Require 2–3 "experience-based specifics" per article, detailing what actually happens on real teams, not just what should theoretically happen.
-
Require at least one structured artifact (like a table, checklist, or framework) per article where relevant.
I swear, internal linking at scale is the first thing to get dropped when a team is under pressure. It matters for topical authority and for helping AI engines understand the relationships between your pages. If it's being done manually, it won't scale, and it'll get skipped on busy weeks.
Freshness operations: Schedule your 30-day update pass the moment you publish. Don't wait to see if a page needs it; just assume it does and review it on a defined cadence.
This is where having a connected workflow really pays off. We use DeepSmith to run our research, briefing, drafting, QA, internal linking, and publishing as a single pipeline. This lets our humans focus on strategy and review rather than assembly. And Autowrite lets you schedule article generation on a cadence so the calendar keeps moving, with humans reviewing instead of starting from scratch. That’s the difference between a system that maintains quality at volume and a team that just churns out filler under pressure.
The "Quality Bar" Rubric That Prevents AI Sameness
Before any article ships, score it on these five dimensions:
| Dimension | Pass | Fail |
|---|---|---|
| POV clarity | Intro argues a position | Intro just summarizes the topic |
| Unique evidence | Includes original data or a process artifact | All claims are generic observations |
| Extractable structure | Every H2 opens with a direct answer | Sections open with context or background |
| Technical readiness | Schema present, crawlable, metadata clean | Technical pass was skipped |
| Post-publish plan | Owner assigned, update date set | "We'll check on it later" |
If two or more of these fail, the draft goes back. Not for a polish, but to add substance.
How Do You Distribute and Iterate So Citations Compound (Instead of Spiking Once and Dying)?
Citations are earned and kept through a post-publish loop: distribution to create signals, monitoring across AI engines, and targeted updates on a defined schedule. I've seen it happen a dozen times: a page spikes in citations and then disappears. The reason is almost always publish-and-forget.
The distribution gap is real. "Published" isn't "seen." AI engines give weight to content that's linked to, shared, and accessed. The consistency of those signals matters.
Simple multi-channel distribution SOP (steal this):
-
Day 0: Publish + run an index request; verify crawl access.
-
Day 1–3: Post to LinkedIn with a direct insight from the article (not just a link); share a blurb in your newsletter; share in a community where it's relevant.
-
Day 7: Repost with a different angle or pulled quote; update internal links from 3–5 older posts that should reference this new one.
-
Day 14: Add clarifying blocks based on comments, questions, or gaps you've noticed in AI responses.
30-day post-publish iteration framework:
-
Run your defined prompts in ChatGPT, Perplexity, Gemini, and Google AI Mode.
-
Note: Are you cited, mentioned, or absent? Which competitor is cited instead?
-
Identify the gap: a missing entity, a weak answer block, an outdated stat, an undefined term.
-
Update deliberately. Rewrite one section opener, add one table, add one FAQ, or refresh one number.
Don't just churn pages daily. Frequent, shallow edits don't help and can even signal instability. Make meaningful, substantive updates on a scheduled cadence.
Distribution doesn't have to feel like a whole separate job. Our ops in DeepSmith have an Agent Library that generates LinkedIn posts, newsletter blurbs, and social threads from any article, in our brand voice. Promotion becomes a standard output of publishing, not a separate project that gets dropped. Repurposing alone doesn't drive citations, but consistent amplification reinforces the signals that support them.
The "30-Day Citation Retention" Update Checklist
Update triggers (act when you see these):
-
A competitor displacing you for a prompt you previously owned.
-
A query cluster your article should answer but doesn't fully address.
-
Outdated statistics or timeframes (anything older than 12 months in a fast-moving space).
-
Vague definitions that an AI might misquote or misattribute.
Update actions:
-
Rewrite section openers to be more direct and quotable.
-
Add a comparison table where you currently have prose paragraphs.
-
Add one concise FAQ question that covers a gap query.
-
Refresh any numbers with current data and a new timestamp.
-
Add a missing named entity (a tool, framework, or company) that belongs in the context.
How Do You Measure AI Visibility and Report ROI to Leadership (Without Hand-Wavy Anecdotes)?
Treat AI visibility like a measurable channel. Leadership won't fund what they can't see trending. Define your prompts, track mentions and citations by platform, benchmark competitors, and connect improvements to pipeline indicators.
Don't fall into this trap: GA4 and Google Search Console won't tell you if you're getting cited in AI answers. They track clicks and impressions from traditional search. AI citations often result in zero-click answers where the user gets what they need without visiting your site. Your citation rate can be growing while your organic traffic stays flat. You need a separate measurement layer.
Core metrics to track:
| Metric | Definition | How to Collect | Who Owns It |
|---|---|---|---|
| Prompt-level mention rate | % of defined prompts where your brand is mentioned | Manual queries or an AI visibility tool | Content lead |
| Citation rate | % of mentions that include a source link to your page | Manual queries or an AI visibility tool | Content lead |
| Page-level citation trend | Which pages are cited, trending up or down | AI visibility tool | SEO specialist |
| Competitive citation share | Your citations vs. competitors for category prompts | Manual or AI visibility tool | Content lead |
| Recency signal | Last-updated date on your cited pages | Content calendar / CMS | Content lead |
Reporting cadence: Monitor weekly for the content team. Send a monthly executive summary with trend data and your competitive position.
Tie this to business outcomes carefully. You can correlate citation wins with a lift in branded search, direct traffic increases, or anecdotes from sales, but be honest about the limits of attribution. The connection is real but not always clean. Overstating it will undermine trust with leadership faster than admitting uncertainty.
This is another area where a dedicated tool makes a huge difference. We use DeepSmith AI Visibility to track our mention and citation rates across major platforms. It gives us a repeatable, platform-specific picture that we just couldn't get from a spreadsheet.
The Executive-Ready One-Slide Summary (What Your CMO Actually Wants)
Your CMO doesn't have time for a 10-page report. Give them this, on one slide, once a month:
-
Where we're cited: Top 3 prompts where our pages earn citations, and which pages.
-
Where we're not: Top 3 priority prompts where we're absent or only mentioned.
-
Top competitor: Which competitor is winning citations we should own, and on which prompts.
-
Biggest gap cluster: The query cluster with the highest business value where we have no citation presence.
-
Next month's actions: 2–3 specific content updates or new articles targeting that gap cluster.
Who Owns AI-Citable Publishing Inside a SaaS Team (and What SLAs Prevent It from Stalling)?
AI citation readiness requires cross-functional ownership. Without assigned roles and defined SLAs, eligibility checks get skipped, updates get deferred, and "AEO" becomes a permanent agenda item that never actually ships. Sound familiar?
Role map:
| Role | Owns |
|---|---|
| Content lead | Editorial stance, prioritization, gatekeeper, iteration decisions |
| Writer / editor | Answer-first blocks, structure, examples, clarity, Gate 1–3 execution |
| SEO specialist | Intent mapping, internal links strategy, on-page QA, Gate 5 |
| Web / engineering | Crawl rules, schema implementation, llms.txt, page hygiene |
| Product / SME | Factual accuracy, product claim review, nuanced constraints |
| Legal / compliance | Claims review for regulated topics (when applicable) |
Suggested SLAs:
-
Brief to first draft: 3 business days
-
First draft to publish-ready: 2 business days
-
Publish to first distribution: 24 hours
-
First publish to first update review: 30 days
If you can only staff three roles: Go with a Content lead (owns stance, gates, and iteration), an SEO/web partner (owns technical eligibility and internal links), and an SME touchpoint (owns factual accuracy). This is the minimum viable structure.
The RACI Mini-Table You Can Copy into Your SOP
If you really want to make sure it gets done, copy this mini-RACI into your content SOP. When a gate isn't assigned, it doesn't happen. Period.
| Gate | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Gate 1: Intent lock | Writer | Content lead | SEO specialist | — |
| Gate 2: Answer-first structure | Writer | Editor | Content lead | — |
| Gate 3: Extraction formatting | Writer | Editor | — | — |
| Gate 4: Credibility + uniqueness | Writer | Content lead | SME / Product | Legal |
| Gate 5: Technical eligibility | SEO specialist | Web / Eng | Content lead | — |
| Gate 6: Post-publish loop | Content lead | Content lead | SEO specialist | Writer |
Copy this into your content SOP. It works.