You ever have that feeling? You see a competitor cited by ChatGPT for a question your buyers ask every day. You know you have better content, a stronger product, and better Google rankings, but there's their brand, not yours.
I'm here to tell you that's not a coincidence. Especially if you're in a regulated or low-trust space like security, fintech, compliance, or health. In these fields, AI engines are incredibly cautious. They aren't just looking for a blog post. They're looking for verifiable legitimacy, with entities they can identify, claims they can cross-reference, and endorsements from sources they already trust.
The brands winning in this new world have realized authority isn't a content strategy. It's a system. You have to make your legitimacy machine-readable, human-believable, and measurable. That's what this is: a playbook you can actually run and defend to your leadership team when they ask what you're doing about "the AI thing."
What 'Brand Authority' Actually Means for AI (It's Not Your Old SEO Game)
Brand authority vs topical authority: what changes when answers are synthesized
We all got really good at topical authority. It was the main goal of the SEO era. You just had to cover every keyword cluster in your niche, and you'd eventually rank. That logic works perfectly when a search engine is just giving you a list of links. It completely breaks down when an AI synthesizes one definitive answer.
AI systems doing retrieval aren't just asking, "Who wrote about this topic?" They're asking a much harder question: "Who can I trust to be right about this?" Topical breadth might get you into the candidate pool for retrieval. Brand authority is what gets you cited in the final answer.
So, brand authority for AI is about entity recognition and credibility signals. Does the AI system know who you are, and does the rest of the internet confirm that you're legit? It's the difference between being a source and being the source.
Why low-trust categories face a higher bar (risk, verification, and ambiguity)
Think of it like this: AI engines have a built-in harm-adjusted trust threshold. If you're in a category where bad information could cause financial, legal, or security damage, that threshold goes way up. Perplexity isn't going to cite some anonymous blog for advice on SOC 2 compliance when a credentialed alternative exists.
This is why you can't just out-publish the problem in regulated industries. I've seen teams try, and it can actually backfire. More content without stronger credibility signals just looks like noise. The signal you need isn't "we wrote 200 articles." It's "we are a verifiable, expert entity, and other trusted sources agree."
The 'Trust Signals' AI Engines Actually Care About
This is where a lot of guides get fuzzy. Let's make it concrete.
Machine-readable trust: entity clarity, consistency, and structured signals
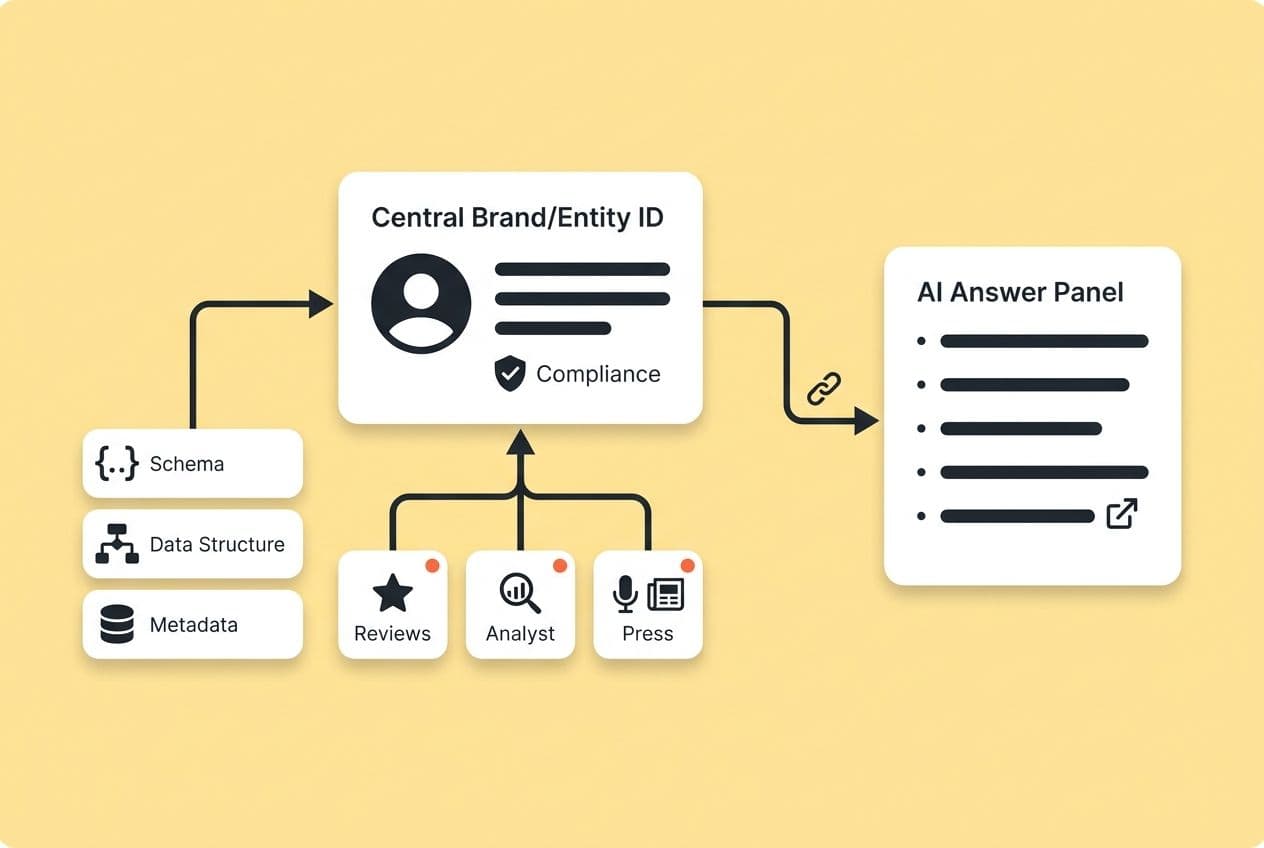
Before an AI can trust you, it has to know who you are with absolute confidence. Entity ambiguity is a silent killer for AI visibility. If your company name, founding date, or description is different on your site versus your LinkedIn profile or other directories, you're handing the AI contradictory information. It gets confused, and a confused AI defaults to ignoring you.
This starts with simple, consistent entity clarity. The same organization name, description, and leadership names, everywhere. This isn't just good marketing hygiene; it's how you help an AI build a confident model of your brand before it even thinks about citing you.
Structured data makes this process faster (and we'll get to a priority list in a minute), but consistency is the foundation.
Human-verified trust: third-party validation that AI can safely lean on
AI systems are cautious. They hate being the only one saying something nice about you. They feel much more comfortable citing your brand when other independent parties have already vouched for you.
For those of us in regulated fields, the most powerful signals are:
- Analyst mentions and industry reports: If Gartner, Forrester, or a credible niche analyst mentions your company, it acts as a huge stamp of legitimacy.
- Customer reviews on verified platforms: G2, Capterra, and Trustpilot are indexed by AI engines and treated as real third-party endorsements.
- Press coverage in trade publications: I'm not talking about press releases. I mean real editorial coverage in outlets that matter in your category.
- Expert contributor bylines: Getting your team's content published on respected external sites shows your expertise isn't just an internal claim.
- Community recognition: Being talked about and recommended in the forums and communities where your buyers actually hang out (like Reddit, Slack communities, or LinkedIn groups).
The logic is simple. AI systems borrow trust from sources they already trust. If those sources mention you, you get to borrow some of that trust.
Content proof vs content volume: what "credible" content looks like under scrutiny
I've seen this mistake a thousand times: confusing a long article with a credible one. A 3,000-word guide full of unsupported claims is, from an AI's perspective, worse than a tight, 800-word piece that backs up every assertion.
In low-trust categories, "credible" content has specific traits. It includes citations to primary sources (like regulatory guidance), clear author credentials, and it's transparent about what it is and isn't claiming. These signals tell both AIs and skeptical human readers that your brand knows the domain well enough to be careful.
The Tech SEO That Directly Feeds AI What It Wants
The priority stack: what to implement first vs later
Don't try to boil the ocean. Run this in order:
- Organization schema: Name, URL, logo, founding date, description, social profiles, contact info. This is the bedrock for reducing entity ambiguity.
- Person schema for key authors and executives: Include credentials, job titles, and links to their profiles. This connects your content to real, verifiable experts.
- Article/BlogPosting schema: With author, date published, date modified, and a reference back to your Organization entity.
- FAQPage or Q&A schema: For pages that directly answer common buyer questions.
- Review/AggregateRating schema: If you have legitimate customer reviews on your site.
- BreadcrumbList and SiteLinksSearchBox: Lower priority, but they help with overall coherence.
Seriously, just get the first two right before you touch anything else. They unlock the most value the fastest.
Entity signals that reduce ambiguity
Beyond structured data, make sure you're telling the same story everywhere. Your Wikipedia page, Wikidata entry, Google Business Profile, LinkedIn company page, and Crunchbase profile should all match. Name, founding date, HQ location, description, leadership. No variations.
The same goes for your products. Name and describe your offerings consistently everywhere they appear. AI systems build models of products too, and inconsistency creates ambiguity that gets resolved by, you guessed it, not citing you.
Content formats AI extracts cleanly
AI systems love clean, structured content. They can more reliably pull information from short declarative headings, defined terms, lists, and summary statements right at the top of a section. Think "answer first, then support," rather than burying the lede in paragraph three.
For regulated fields, structured explainers (what a term means) and process documentation (step-by-step guides) are gold. They extract cleanly and are easy to verify, which makes them great citation fodder.
Common failure modes in regulated spaces
These four things kill AI trust faster than anything else:
- Inconsistent entity signals: Different company name formats, no schema, no Knowledge Panel. It's a mess.
- Thin authority pages: An "About" page with two paragraphs and no names or credentials. It looks like you're hiding something.
- Unverifiable claims: Using marketing fluff like "the leading platform" without attribution. AIs can't verify superlatives, so they just ignore them.
- Stale content: In our world, outdated content isn't just old, it's a liability. Pages without update dates or a visible review process look untrustworthy.
How to Prove Your Expertise When Legal Is Watching
This is the part everyone in a regulated industry struggles with. How do you show you're an expert when you can't make big, bold claims?
The "evidence artifact" library: what you can publish when you can't publish big claims
You don't need case studies with specific ROI numbers to prove you know your stuff. We learned to build a library of "evidence artifacts" that work even in the most compliance-heavy environments:
- Process documentation: Writing "How We Evaluate X" or "Our Framework for Assessing Y" proves you've actually done the work.
- Annotated checklists: Practical, specific guides with little notes that only an experienced practitioner would think to add.
- Common failure analyses: A post on "Why X Approach Fails in Practice" shows you've seen the patterns in the real world.
- Anonymized aggregate observations: Something like, "Across the implementations we've seen, teams that skip X consistently hit Y problem." No individual data, just real patterns.
- Regulatory interpretation notes: Your team's take on new guidance, framed clearly as your perspective, not as legal advice.
Each of these signals deep experience without needing a single claim that will send your compliance team into a panic.
Controlled case narratives: how to show outcomes without unsafe promises
If you can publish a customer story, use guardrails. Focus on qualitative outcomes ("reduced the time their team spent on X"). Avoid specific percentages unless they are airtight and approved. Always include context about industry and company size, and add explicit language that results vary.
Honestly, this framing doesn't just protect you legally. It sounds more credible to a skeptical buyer anyway. "This is what we helped one team navigate" is a much stronger signal than "we drive 40% efficiency gains," because one sounds real and the other sounds like marketing.
Trust-building page elements teams forget
These pages probably exist on your site right now but are totally underdeveloped. AI systems look at them.
- Author bios with credentials: Name, title, certifications, years of experience, and links to external profiles.
- An editorial standards page: Explain how you research, write, and review content. This is a direct signal of quality.
- Content update policies: A "publish date" and "last reviewed date" on every single piece. This alone is a huge credibility lift in regulated fields.
- "About" page depth: Your leadership team with linked profiles, your company history, and the regulatory context you work in.
How to Win on Perplexity vs. Google vs. ChatGPT
Not all AI engines are the same, so your strategy shouldn't be either.
Platforms that cite sources vs summarize without attribution
Perplexity is great because it shows its work with linked sources. To win here, you need to be indexed, have clean content structure, and build up those third-party mentions.
Google's AI Overviews lean heavily on existing E-E-A-T signals and search rankings. If you already do well on Google, you have a head start.
ChatGPT (with browsing) is a bit of a black box with its citations. It tends to favor brands it recognizes from its vast training data, so your overall third-party footprint is critical here.
Gemini uses Google's knowledge graph, so having a clear entity and a strong Knowledge Panel is super important.
Claude is more conservative and often summarizes without direct links. The way to build authority for Claude is to become part of the broader information ecosystem it learns from. It's a long game.
Where platforms "learn" about you
These platforms ingest information from all over: your website, third-party directories, news coverage, community forums like Reddit, and even YouTube video transcripts. A brand with a presence across many of these gives the AI more data points to triangulate, which builds its confidence to cite you.
How to Measure This So You Can Get (and Keep) Budget
This is how you turn a good idea into a program your leadership will actually fund.
Define what you're measuring: mentions vs citations vs sentiment vs share of prompts
First, get your terms straight before you build a single dashboard.
- Mention rate: How often does your brand show up in an AI answer, with or without a link? (This is about brand recognition).
- Citation rate: How often do you show up with a direct link? (This is about content authority).
- Sentiment: Is the mention positive, neutral, or negative?
- Share of prompts: For the questions you care about, what percentage of answers surface your brand versus competitors?
These are all different numbers that tell you different things about your progress.
Build your prompt set like a buyer-journey portfolio
Your list of prompts shouldn't just be your marketing keywords. Think like a real buyer asking for help.
- Category-level: "what's the best tool for SOC 2 compliance management?"
- Problem-specific: "how do companies manage vendor risk in regulated industries?"
- Comparison: "[Our Brand] vs [Competitor] for [use case]"
- Expertise: "what should I look for in a [category] vendor?"
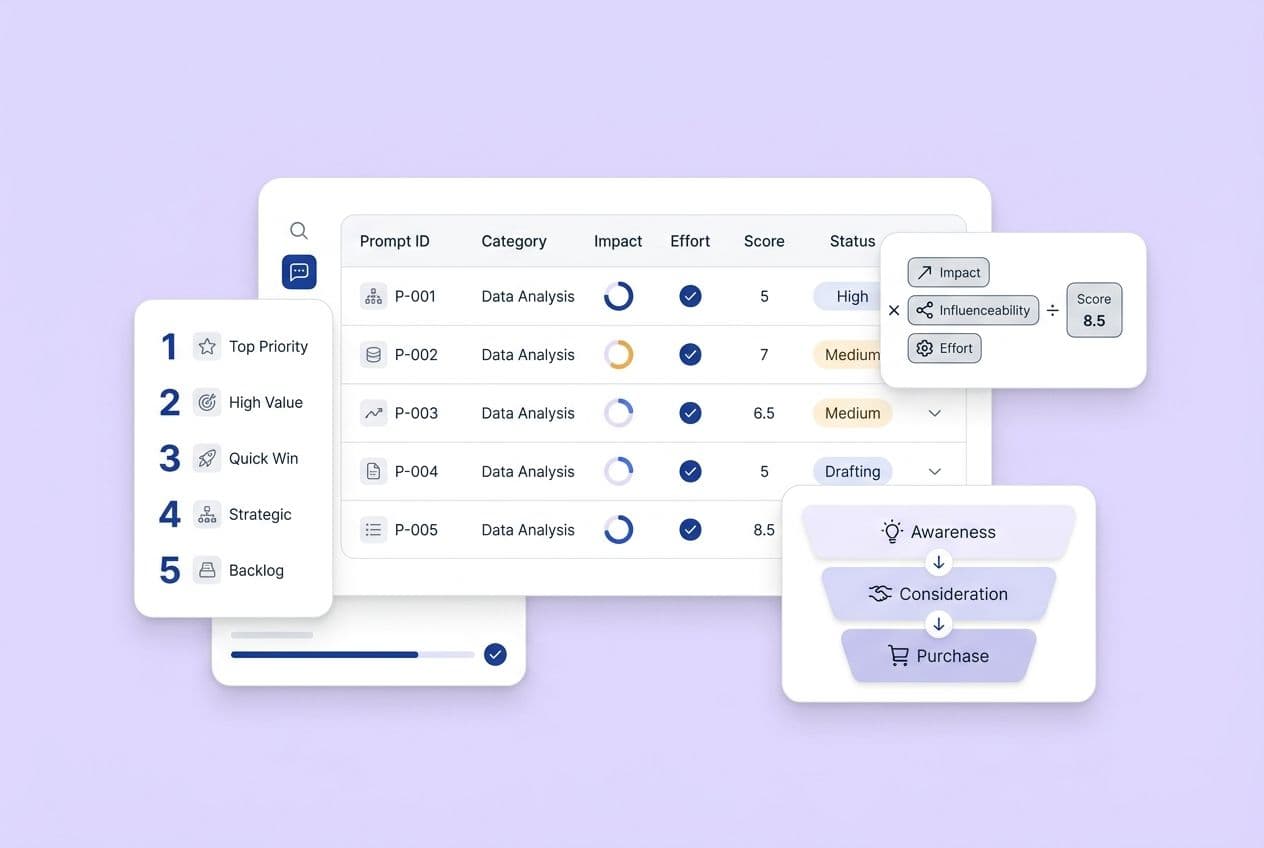
Track these prompts across platforms and log the results. You need at least 60 days of data before you can see real trends. The key is to define a stable set of prompts and track them consistently. This was such a pain to do manually that we built DeepSmith AI Visibility to handle it. You define your buyer prompts, and it tracks your mention and citation rates across all the major platforms so you can see trends, not just snapshots.
How to read trendlines
So what does "good" look like? A rising mention rate on your category prompts over 90 days is great. A growing citation rate on comparison prompts is a sign your evidence-backed content is working.
What to watch out for? Spikes on a single prompt are often just noise. Also, if your citation rate is rising but your overall mention rate is flat, it means you're getting cited for specific things but not broadly recognized. That's a signal to work on your third-party validation.
How prompt-level and page-level tracking makes optimization iterative
Measurement is useless if it doesn't tell you what to do next. If a prompt isn't surfacing your brand, you need to know why. Is it an awareness problem (no pages on that topic) or a quality problem (pages exist but aren't trusted)? We built DeepSmith AI Visibility — Pages to solve this. It shows you which of your pages are earning citations and how that's trending, so you can connect a performance gap back to a specific piece of content and fix it.
How to Figure Out Why a Competitor Is Winning and Build a Plan to Beat Them
Step-by-step: extract competitor-cited sources, classify the proof, then map to your missing assets
When you see a competitor getting cited over and over, don't just get frustrated. Run this playbook:
- Identify the specific pages AI is citing. Grab the source links from the AI response. (Perplexity makes this easy).
- Classify the proof type. What makes that page so trustworthy? Is it the author's credentials? External data? Deep regulatory detail?
- Find the gap in your own coverage. Do you have a page on the same topic? Does it meet the same standard of proof?
- Turn gaps into a content backlog. Each gap becomes a specific brief: topic, required proof, author needed, structured data required.
Run this analysis monthly. AI preferences change as new content gets indexed.
What to copy vs what to differentiate
The goal is not to write a slightly worse version of your competitor's article. Cover the same topic at the same level of proof, but find a way to differentiate. Bring your own unique perspective, use a different type of evidence (maybe a different case narrative), and lean on your own experts' credentials.
The win comes from out-credentialing them, not just out-publishing them.
How citation benchmarking accelerates this workflow
Doing this all by hand is slow, and you'll miss things. This is another area where we got tired of manual work. DeepSmith AI Visibility — Competitors shows you which competitor pages are earning AI citations and even tracks their sitemaps so you know what they're publishing. You can see what's working for them and feed that intel directly into your own content plan.
The 30-60-90 Day Plan for Building Authority from Scratch
Days 1–30: fix entity clarity + publish "trust anchors" first
Lock in your entity signals. Update your Organization schema, author schemas, and Google Business Profile. Do a quick audit of your name, address, and description across LinkedIn, Crunchbase, G2, etc., and make them consistent.
Then, publish 2-3 "trust anchor" pieces. A big guide on your core category, a piece on the regulatory context, and an editorial standards page. These signal immediate credibility.
Days 31–60: ship experience proof + distribution consistency
Start building your evidence artifact library. Publish one piece of process documentation, one controlled case narrative, and one "common failure modes" analysis. These signal you've been in the trenches.
At the same time, get consistent with distribution. Every piece goes on LinkedIn, in your newsletter, and you should aim to contribute at least one external article or expert quote to a relevant publication. Consistency beats volume here.
Days 61–90: expand third-party validation + tighten measurement loops
Start actively working your review profiles on G2 or Capterra. If it makes sense for you, start reaching out for analyst coverage. Target mentions in your category's active communities. By now, you should also have 60 days of prompt tracking data, which is enough to see early trends and figure out which topics need more attention.
How to Run This as a System, Not a Series of Fire Drills
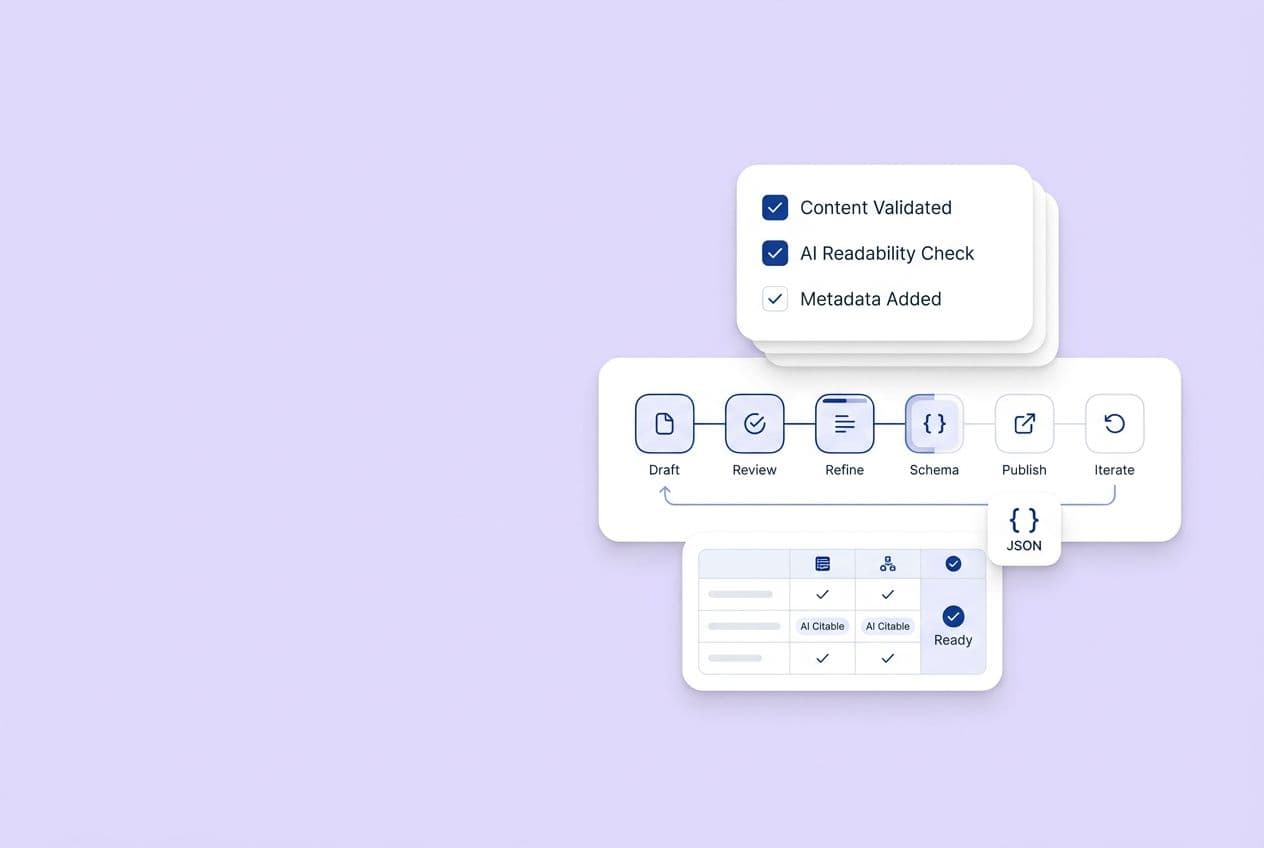
The "citation-ready" workflow: research → brief → draft → QA → publish → distribute → measure
This has to be a cross-functional workflow, or it will fail. A single person can't own this.
- Research: Keyword and prompt analysis to find the topic.
- Brief: Defines the angle, proof types, author, and compliance rules.
- Draft: Written to evidence standards, not just SEO.
- QA: Compliance, editorial, and technical (schema) reviews.
- Publish: With all metadata and attribution.
- Distribute: Multi-channel promotion starts immediately.
- Measure: Track prompt performance and page-level citations.
Governance for regulated industries: review steps, claim boundaries, and transparency
The governance layer is what keeps you safe. You need a documented list of claims that require legal review, a standard for what "verified" means, and a public editorial policy. This also applies to your own use of AI. In a low-trust field, using AI to generate content without human oversight is a fast way to destroy the authority you're trying to build. The only safe model is "human-in-the-loop," where AI assists but a qualified expert is always the final judge.
Where an end-to-end content pipeline reduces bottlenecks
The biggest killer of this whole process is the QA bottleneck, with reviews happening one after another. That pain gets worse when your content team is also trying to do all the upstream research and downstream distribution. This is why we built DeepSmith Content Studio. It connects the whole pipeline from research to publishing so your team can focus on the high-judgment work. This is reinforced by DeepSmith Deep IQ, a structured source of truth that grounds all content in approved claims. And for distribution, our Agent Library can repurpose any published article for LinkedIn, newsletters, and social media, creating the multi-channel consistency that AI engines look for.
Build your AI authority baseline (and turn it into a content plan)
The best way to get started is to figure out where you stand today. Which AI platforms mention you, for which prompts, and how do you stack up against your competitors?
Start by defining 10-15 of your most important buyer prompts. These are the questions your ideal customers are asking AI tools. Run them across ChatGPT, Perplexity, Gemini, and Google's AI Overviews. Log what you find. Then, map the gaps you see to the trust signals we've covered here. Is it an entity problem? A lack of third-party validation? A gap in content proof?
That map becomes your prioritized roadmap. It's the defensible plan your leadership team has been asking for.
If you want to skip all that manual tracking and run this like a real performance channel, DeepSmith AI Visibility provides the prompt tracking, page-level attribution, and competitive benchmarking to make it all continuous. And Content Studio helps you turn that roadmap into a production queue. The whole system is built to run this as a program, not a one-off project.