I've been there. You search your main use case in ChatGPT and a competitor shows up. You try a different angle. Another competitor. Your company is nowhere to be found.
The gut reaction is to panic and start rewriting everything. Sharpen the intro, add more headers, cram in an FAQ section. But you're editing blind. You have no idea which prompts are triggering those citations, which of your pages are already close to winning, or why the competitor's page won instead of yours. So you burn weeks rewriting articles, only to see zero change in the outcome. I've lived that frustration.
The right move is the exact opposite of how most content teams operate. You have to audit first. Don't rewrite a single word until you know what to change and why.
This is the citation-first audit playbook I wish I'd had. It's for lean SaaS teams who don't have time for a data science project. It's not a formatting checklist, but a repeatable process to show you where you stand, what's blocking you, and what to fix in a week.
What should you measure in an AI citation audit (mentions vs citations vs links vs sentiment)?
Before you even think about opening a spreadsheet, you need to get clear on what you're measuring. "Checking if we show up in AI" isn't a measurement. It's a vibe check, and vibe checks don't build a prioritized backlog.
The four outcomes to track (and what each one tells you)
I've found there are four distinct things worth tracking. They're not interchangeable, and knowing the difference is half the battle.
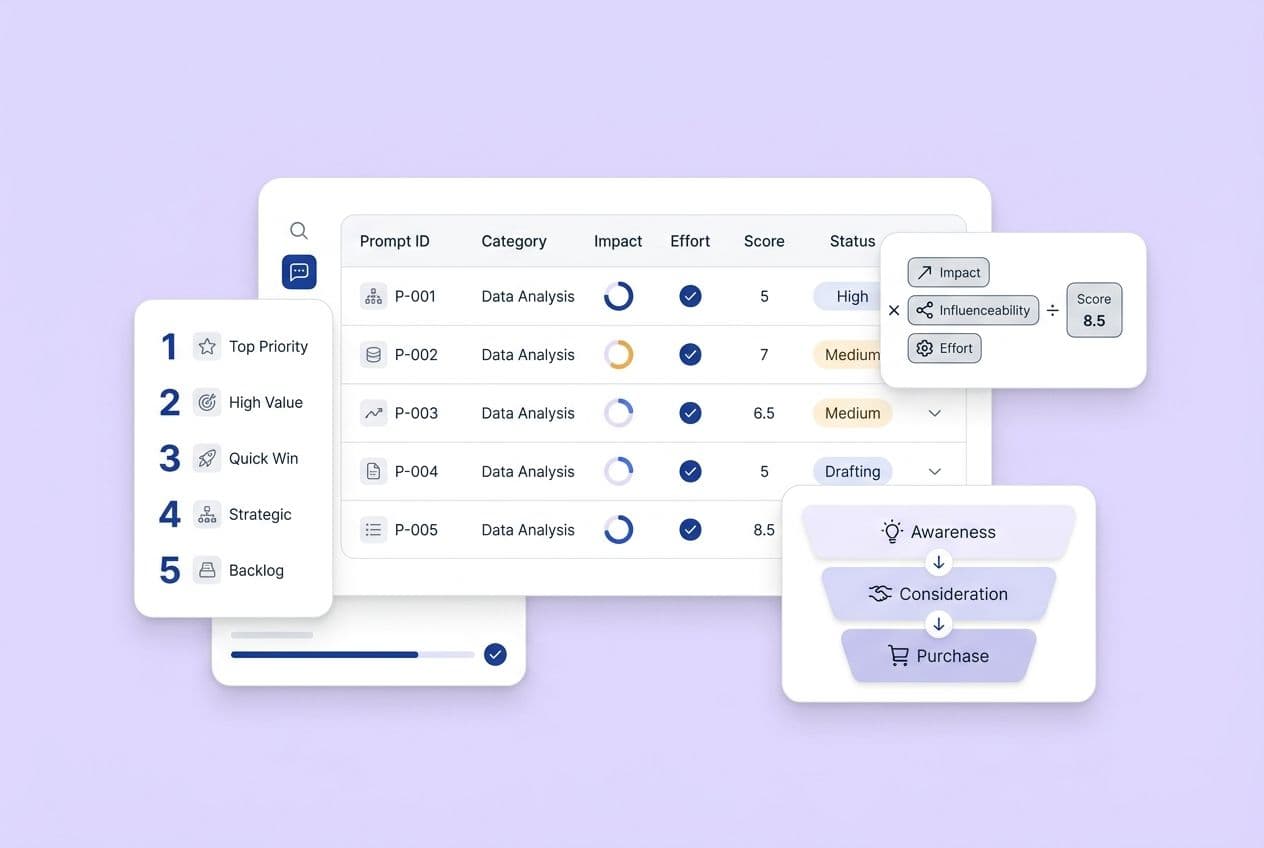
Mention rate shows how often your brand name appears in an answer. A mention doesn't mean you're trusted or cited as a source. It just means the model knows you exist in the context of that topic. It's a start.
Citation rate is how often an AI answer directly attributes something to your content. This usually looks like a linked source, a named URL, or a little bracketed number. This is a much stronger signal than a mention. The model is telling the user, "I got this information from here."
Link presence is simply whether a citation includes a clickable URL. Perplexity is great about this and almost always links. ChatGPT often just name-drops you. The distinction matters for driving traffic, but both are valuable for brand positioning.
Sentiment/context is about how you're being framed. Are you the go-to solution? A niche option? An "also-ran"? Or worse, are you the example of what not to do? The sentiment of a citation is what determines if that mention actually helps you or hurts you.
AI visibility vs AI citability (the failure modes are different)
This is the diagnostic split that most teams miss, and we definitely did at first. We'd lump "we don't show up in AI" into one big problem. It's actually two very different problems with totally different fixes.
An AI visibility problem means you're not mentioned at all. The model has zero connection between your brand and the topic. This is an entity and content problem. You need to build your topical authority so the AI even knows you're part of the conversation.
An AI citability problem means you're mentioned but not linked or cited as a source. The model knows you exist but doesn't trust your content enough to point to it. This is usually a structure and evidence problem. Your content isn't written in a way that an AI can cleanly pull an answer from it.
Run through your prompt list (we'll build this next) and label each result. Most teams I talk to discover they have both problems, just in different ratios depending on the topic. That ratio tells you what to fix first.
The minimum viable metric set for a small SaaS team
You don't need a spreadsheet with 14 columns. Seriously. Track five things for each prompt:
- Prompt text
- Platform tested
- Mention (yes/no)
- Citation/link (yes/no)
- Sentiment label (positive / neutral / negative / incorrect framing)
Do this for 20–30 prompts on three or four platforms. That's it. That's your first audit. You'll have more than enough signal to build a real backlog without getting lost in the data.
Which prompts and platforms should you audit to reflect real buyer behavior?
This is where most teams go wrong before they even start. I've seen it happen: they test their own branded queries, find out they don't show up, and freak out. But your actual buyers aren't discovering new tools by searching for your company name. Getting the prompts right is everything.
A prompt selection method: category prompts, problem prompts, "best tools" prompts, and comparison prompts
I recommend building your prompt list across four categories that map to how real buyers think and search.
Category prompts are for broad awareness. Think "What is [your category]?" or "How does [your technology] work?" These tell you if your brand is part of the introductory conversation in your space. If you're not showing up here, you probably have an AI search visibility gap.
Problem prompts are the money prompts. "How do I [solve this specific pain point]?" or "What's the best way to [get this job done]?" This is where your potential customers are living. If you're invisible here, you're missing out on the entire discovery stage.
"Best tools" prompts are high-intent. "Best [category] tools for [persona]" or "Top [tool type] for [use case]." AI platforms churn out these lists constantly. Getting on the list is a huge win.
Comparison prompts are for the decision stage. "[Your brand] vs [Competitor]" or "What's the difference between [Tool A] and [Tool B]?" These test whether your positioning is clear and if your comparison pages are actually working.
For your first audit, just aim for 5–8 prompts in each category. That's 20–32 prompts total, which is completely manageable in a week.
How many prompts is enough for your first audit (and why "more" backfires)
Twenty to thirty prompts will show you your biggest gaps. I promise. If you go for more, you'll spend three days collecting data and zero days acting on it.
The big trap here is scope creep. You'll start thinking of every possible edge case and long-tail variation. Resist that urge. For the first audit, your goal is to find a clear signal, not to achieve perfect comprehensiveness. You can always add more prompts next month once you've got the process down. A good first audit is one that gets done. A perfect one never ships.
Platform differences that change how you interpret results (ChatGPT vs Perplexity vs Google AI)
You can run the same prompt on three platforms and get wildly different results. You have to know why.
Perplexity cites everything and links its sources. It behaves the most like you'd expect from an SEO perspective. The sources are visible, clickable, and often correlate with pages that have clean structure and high topical authority. If you're not showing up in Perplexity, check your structured content first.
ChatGPT tends to synthesize answers without always citing where it got the info. When it does cite something, it's usually a highly authoritative domain with a very specific, citable claim. Getting cited in ChatGPT is a high bar, but just getting mentioned is still a meaningful win.
Google AI Mode / AI Overviews feels a lot like traditional SEO. Pages that rank well in organic search seem to have a better shot of appearing. But it also clearly favors structured content, like putting a direct answer (a BLUF, or "bottom line up front") right at the top of the page.
Gemini and Claude are worth checking too, but for a first audit, you can test them more lightly. I'd start with Perplexity, ChatGPT, and Google AI as your main three.
Where prompt discovery usually breaks (branded bias, internal jargon, and non-buyer queries)
I've seen three things kill an audit's value before it even begins.
Branded bias: Your team writes prompts using your company's internal language, not the language your buyers use. If your ideal customer calls it "workflow automation," but you're testing prompts with your branded feature name, you're just testing brand recall, not discovery.
Internal jargon: The terms you use for your category might not be what buyers are using. Before you lock in your prompts, check them against sales call transcripts or support tickets to make sure you're using real customer language.
Non-buyer queries: Your engineers might think about the space in a super-technical way, but your Director of Marketing probably doesn't. Keep the prompts anchored to real buyer problems and buyer language.
A quick fix for this: have someone who wasn't involved in naming your product write the first draft of the prompt list. Or just pull your queries straight from your organic search console data.
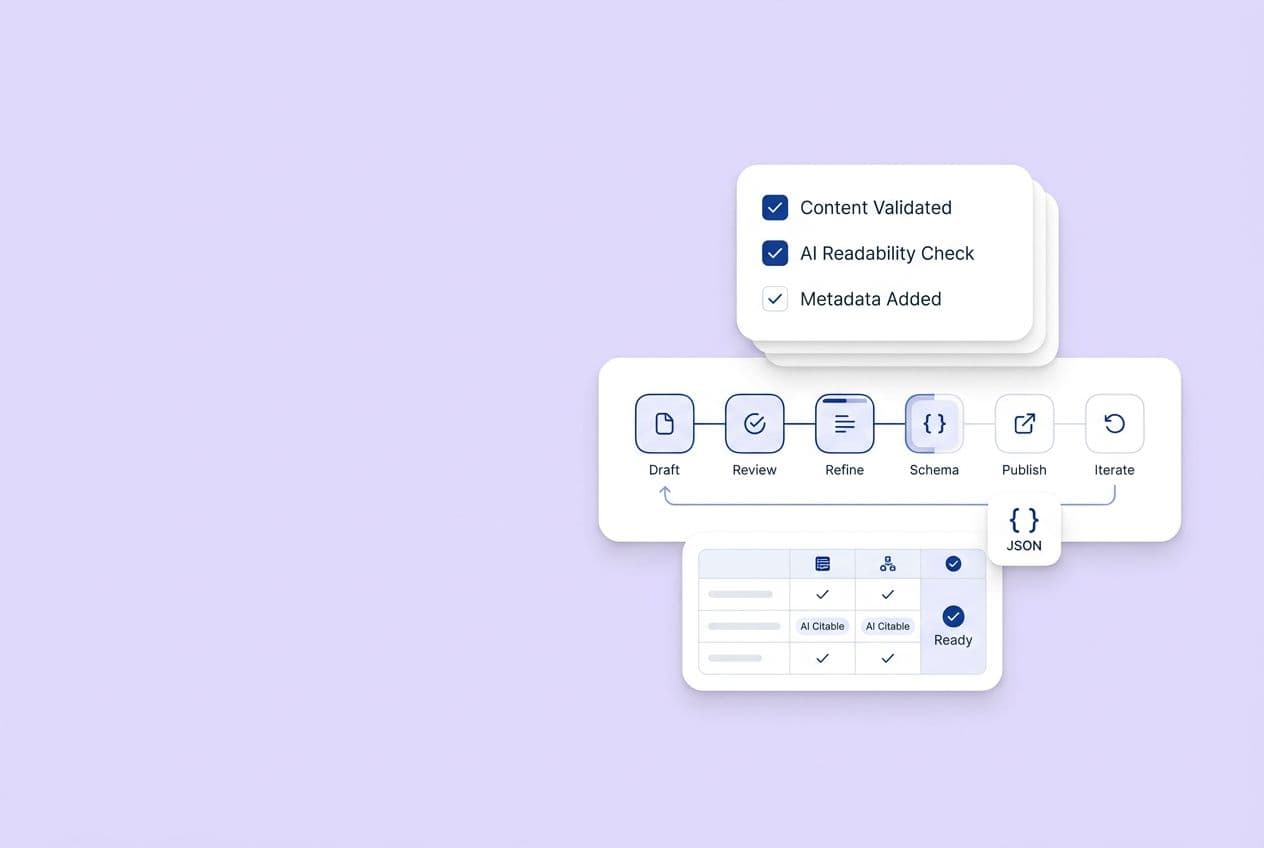
How do you run a citation audit in a week without rewriting anything?
This is the five-day sprint that gets you a prioritized backlog. The key is giving yourself permission to not rewrite anything until Day 5.
Day 1 — Set up your audit sheet and define pass/fail criteria per prompt
Create that simple spreadsheet: Prompt, Category, Platform, Mention (Y/N), Citation/Link (Y/N), Cited URL, Competitor URLs cited, Sentiment, Notes. Add a "Priority" column.
Before you start, define what "good" looks like for you. For problem-prompts, for example, maybe your goal is a 50% mention rate. For comparison prompts, maybe it's an 80% citation rate. The specific numbers are less important than having a consistent benchmark.
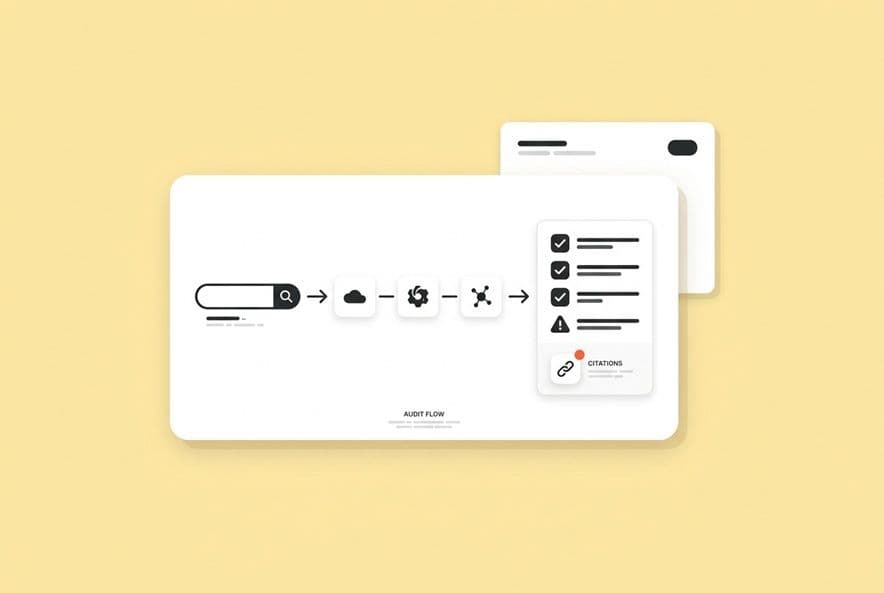
Day 2 — Capture AI answers consistently (what to record so it's auditable later)
Run every prompt on your three core platforms. For each one, either paste the full text of the answer or take a screenshot. You need the literal output so you can compare it later. Don't paraphrase. Also log every single URL that gets cited.
AI outputs can be inconsistent. I recommend running each prompt twice per platform. If the results are wildly different, that volatility is itself a signal worth noting.
Day 3 — Attribute citations to page types (blog post vs landing page vs glossary vs docs)
Now, look at all the URLs that were cited, both yours and your competitors'. Categorize them by page type: blog post, landing page, glossary, docs, etc.
You'll start seeing patterns. Are glossary pages winning all the definitional prompts? Are comparison pages dominating the "vs" queries? This tells you exactly what kinds of content gaps you need to close or need to invest more in.
Day 4 — Compare against competitors and label "why they won"
For every prompt where a competitor got cited and you didn't, force yourself to write one hypothesis in the Notes column. Keep it short. Usually, it boils down to one of these:
- Structure advantage: Their page answered the question in the first paragraph. Yours buried it.
- Evidence advantage: They cited specific research. You gave generic advice.
- Freshness advantage: Their page is from this year. Yours is from 2021.
- Format advantage: They have a dedicated page for the topic. You have one paragraph in a long article.
- Authority advantage: Their domain just gets cited for this stuff more often than yours.
You'll see the same reasons pop up over and over. Those patterns are your highest-priority fixes.
Day 5 — Convert findings into a prioritized backlog (no-rewrite triage)
Now you build your to-do list. I group fixes into four types, ordered by how easy they are versus their impact.
- Technical/structural fixes (low effort, high impact): Add a direct answer to the top of a post. Fix a missing
dateModifiedin your schema. These are 30-minute jobs that can improve citability fast. - Structure edits (medium effort): Rewrite section openings to be answer-first. Add a comparison table.
- Evidence upgrades (medium effort): Add a stat, a named framework, or a sourced claim.
- New assets (high effort): This is for confirmed gaps where you have nothing and competitors are cleaning up. Build that missing comparison page or glossary entry.
Notice that "full rewrite" isn't on the list. You should only do that if the audit shows a massive positioning or accuracy problem. Most fixes are surgical. Systems like our DeepSmith AI Visibility tools can automate this discovery, helping turn your audit into a data-backed backlog without the manual grind.
What are the most common reasons your content isn't getting cited (even if it ranks)?
Ranking in Google and earning AI citations are related, but they are not the same thing. I've seen pages rank #3 organically and get completely ignored by every AI engine. Here are the most common (and fixable) reasons why.
Structure problems: unclear section openings, missing BLUF, and "context-first" writing
AI systems are built to extract answers. If your page opens with a long, winding intro instead of the answer, the extraction fails. We used to write these beautiful, context-setting paragraphs. Turns out, AIs hate them. They want the answer, now.
The fix is simple: audit the first sentence after each H2 and H3. It should directly answer the question implied by the heading. If it doesn't, rewrite just that one sentence.
Trust problems: weak sourcing, unverifiable claims, and generic summaries
Saying "studies show" is not a citation-ready claim. Neither is "experts agree." AIs are getting better at favoring content with specific, attributable evidence. Your most important claims need to be anchored to something real: a named study, a specific number, a documented framework. If your content is just a generic summary of what everyone already knows, there's no reason for an AI to prefer it.
Freshness and maintenance problems (including dateModified misuse)
"Fresh" doesn't just mean you republished the page with a new timestamp. AIs, especially Google's, are smart enough to tell the difference. They look for actual changes: new content sections, updated stats, real edits to the body. If a page hasn't been substantively changed in 18 months, a real update is in order.
Machine-readability problems: messy templates and missing structured data
Schema markup isn't a magic bullet, but not having it is a real disadvantage. Things like FAQ, HowTo, and Article schema give AI systems clean signals to work with. If your CMS template is a mess of broken heading hierarchies or multiple H1s, that's worth fixing before you even touch the copy.
How do you audit and fix semantic drift without turning updates into an editing marathon?
Semantic drift is what happens when your content slowly starts to say something different from what it's supposed to. It's a quiet but dangerous problem, especially when you're updating for AI citations, because the pressure to get cited can make you inflate your claims.
What semantic drift looks like in SaaS content (beyond "tone")
Drift isn't just your tone changing. In SaaS content, it's more concrete:
- Claim inflation: An article that originally said your tool "helps reduce" something gets edited over time and now says it "eliminates" it. That's a huge citation risk.
- Positioning creep: A page for SMBs gets updated with enterprise examples, and now it's not really for anyone.
- Feature misstatements: A how-to guide still references a feature you deprecated six months ago.
- Persona mismatch: A technical article gets a "friendly" update from a marketing writer, and now it attracts the wrong audience.
A quantitative-ish checklist: drift signals you can score during reviews
You don't need a linguistics degree for this. Just use a simple checklist before and after any update.
- Does every product claim still match your product docs?
- Does the language (pain points, terminology) match the target persona?
- Are any claims stronger than what you can actually prove?
- Has the core answer of the page stayed the same?
- Does the update introduce any new, unapproved positioning?
If you get more than two "no's," that update needs a proper positioning review before it goes live.
The remediation workflow: change logs, claim boundaries, and "single source of truth" updates
The fix for drift is a system. We created a "claim boundary" document. It's just a short list of approved claims and phrasing for our key product areas, cleared by both marketing and product. Any update gets checked against it.
This is something we baked into DeepSmith's Deep IQ. It stores your positioning and claims as a source of truth that shapes every draft, so drift can't creep in. If you're doing it manually, a shared doc with locked-down claim language works wonders.
How do you measure (and improve) the sentiment/context of AI citations?
Being cited is not the same as being recommended. A citation can frame you as the complicated option, the thing to avoid, or just a footnote. For a citation to actually convert a customer, the sentiment has to be right.
The citation context categories to label (positive, neutral, negative, incorrect framing)
Just add a sentiment column to your audit sheet and use these four simple labels:
- Positive: The AI recommends you or describes you as a strong solution.
- Neutral: The AI mentions you factually but without any recommendation. "Brand X is a tool that does Y."
- Negative: The AI cites a complaint or limitation that makes you look bad.
- Incorrect framing: The AI gets your product completely wrong. Wrong use case, wrong persona. This is a five-alarm fire and your top priority to fix.
What to do when you're cited but framed poorly (counter-narratives and clarification assets)
If you're getting neutral or negative hits, find the source page and the sentence that triggered the framing. Then you have a few options:
- Add a clarifying section higher up on the page to reframe the claim.
- Create a dedicated "when to use us" or comparison page to give the model a cleaner, more positive source to pull from.
- Tighten the definition of your product on any page where it's introduced.
Don't delete content just because it's unflattering (if it's accurate). Just make sure your accurate-and-favorable content is more prominent and easier to extract.
How to reduce "wrong brand for this job" mentions
If AI systems keep putting you in the wrong bucket, it's often a sign that your own content is too vague about who you're for. Positioning like "for teams of all sizes" is a recipe for this. The model can't match you to a specific buyer, so it either misfiles you or leaves you out. Be specific about who you are for and who you are not for.
How do you operationalize citation audits in your content workflow (cadence, owners, and KPIs)?
An audit you run once is just a project. An audit you run monthly becomes a system that actually improves your results.
A monthly operating rhythm that doesn't disrupt publishing
Here's a simple rhythm that works for a small team:
- Week 1: Run the prompts (2–3 hours, one person). Update the audit sheet.
- Week 2: Review what's changed. Tag new gaps and add fixes to the backlog.
- Week 3: Execute the highest-priority fixes. Aim for 4–6 pages a month.
- Week 4: Review your work. Get ready to check if the fixes moved the needle next month.
The whole cycle shouldn't take more than 6–8 hours of team time per month. If it is, you've made it too complex.
KPIs that show progress without pretending you control the models
You can't force ChatGPT to cite you. But you can create the conditions to make it more likely. Report on the trends:
- Citation rate by prompt category (month-over-month)
- Mention rate vs citation rate gap (is it closing?)
- % of prompts where your brand is present (coverage)
- Sentiment distribution (% positive vs. neutral)
- Pages with at least one citation (the absolute number)
Avoid reporting raw citation counts. A number without context is meaningless.
A simple ROI model for deciding what to update vs what to leave alone
Not every page is worth fighting for. Before you add a fix to the backlog, run it through this quick filter:
- Traffic potential: Does this page serve a high-value prompt?
- Effort to fix: Is this a 30-minute fix or a 3-day rewrite?
- Competitive gap: Are you just one or two changes away from winning?
- Business alignment: Does a citation here actually drive the right kind of buyer?
If a page fails two or more of these, just leave it alone for now. "Do nothing" is a perfectly valid and strategic decision.
What about privacy and compliance considerations?
Be smart about this. Don't paste sensitive company or customer data into public AI models. Ever. Use anonymized prompts. When you're looking at AI tools, check their data handling policies. And have a clear internal policy on how you disclose your own use of AI.
Tooling vs manual: evaluation criteria for cross-platform monitoring
A spreadsheet is fine for 30 prompts, but it breaks at 100. If you're looking at tools, ask: does it track mentions and citations separately? Does it show competitor data? Does it cover all the platforms you care about? For teams that want to connect the audit directly to the content pipeline, an integrated platform like our DeepSmith Content Studio can handle the whole process from research to QA, helping your audit insights turn into published content faster.
Build a repeatable AI citation audit system (without adding headcount)
The point isn't to run one perfect audit. It's to build a monthly routine that keeps your backlog focused on fixes that will actually move the needle. Start small: 20 prompts, three platforms, one simple spreadsheet. Run it once, build your backlog, and run it again in 30 days.
If you want to automate this process and connect the findings directly to your content work, that's what I built DeepSmith for. Our AI Visibility suite handles the measurement, and the Content Studio handles the execution, turning insights into published updates that stay on-brand.
How do I audit AI citations across ChatGPT, Perplexity, and Google AI without spending all week?
Batch your work. Run all 30 prompts in Perplexity, then do them all in ChatGPT, then Google. Just collect the data. Don't analyze anything until you're done. The whole collection process should only take a few hours.
How can I detect semantic drift in content updates without relying on "gut feel"?
Use a simple checklist before and after you edit. Do claims match docs? Does the language match the persona? Are claims exaggerated? Has the core answer changed? If you get two or more red flags, it needs another look.
How do I track whether AI mentions of my brand are positive, neutral, or negative?
Add a sentiment column to your audit sheet with four labels: positive, neutral, negative, incorrect framing. Paste the exact sentence where you're mentioned—don't summarize—so you can trace the framing back to the source.