You've seen it happen, right? Maybe you've lived it. A draft comes back from your new AI tool and it sounds fantastic. The tone is confident, the phrasing is perfectly on-brand. And then your subject matter expert (SME) reads it.
They find a product capability that doesn't exist, a competitor comparison that gets the pricing all wrong, and a stat cited to a study that's apparently a ghost. The content sounded right. But it wasn't.
I've been there, and it's a trap. It's the exact mistake that catches so many good content leaders when they're evaluating AI platforms. We get so focused on testing for brand voice that we forget to test for factual reliability.
Let me be blunt: getting the voice right is table stakes now. The real question, the one that determines if your AI investment pays off or just creates a mountain of hidden editing work, is this: can the platform produce verifiably accurate content in your world? With your specific jargon, your data, and your team's tolerance for risk.
This article is the vendor-neutral evaluation framework I wish I'd had. It's not a generic warning about hallucinations or a sales demo. It's a repeatable test plan you can run on your shortlist this week to get a real answer.
What does "factual accuracy" mean in an AI content platform (and what it doesn't)?
Factuality vs brand voice vs originality vs "sounding confident"
These four things get tangled up all the time when teams are looking at new tools. I've seen it cost people a lot of money and frustration, so let's pull them apart.
- Brand voice is your tone, style, and phrasing. A platform can nail your voice and still invent a statistic out of thin air.
- Originality is about being unique. That's important for SEO, but it has nothing to do with being true.
- Sounding confident is the most dangerous impostor of the bunch. Language models are trained to be fluent and sound self-assured. That fluency has zero correlation with accuracy. An AI can tell you with perfect grammar that your competitor offers a feature they actually killed two years ago.
- Factual accuracy is about one thing: are the claims in the content true, traceable, and current? This is what determines whether your content builds trust or quietly burns it to the ground.
The 4 accuracy dimensions content teams should score
When you evaluate a platform, you need to score its output across four distinct areas. Not just a fuzzy "is it good?" but a real, hard score.
- Claim correctness: Is the statement factually true? Can you prove it against a source you trust?
- Source grounding: Is the claim tied to a real, accessible source? Can your reviewer check it without having to become a private investigator?
- Freshness: Is time-sensitive info (like pricing or stats) actually current? Does the AI know what it doesn't know about something that happened last week?
- Domain specificity: Does the accuracy hold up in your specific, nerdy niche, not just on broad topics? This is the one where most general-purpose platforms fall apart.
Use these four dimensions as the simple backbone of your scoring sheet.
Which hallucinations actually break SaaS content (and how to spot them fast)?
Fabricated sources and citations
This one is brutal because it's designed to trick a busy team. The AI will cite a real-sounding study from a real-sounding organization, but the study itself is a phantom. It's just plausible enough that your editor, who has ten other things to do before lunch, gives it a pass. We learned this the hard way: your QA process has to include actually opening every source. Spot-checking won't cut it.
Conflation and "almost-right" errors
These are the errors that give me nightmares because they're so hard to spot. The model knows two true things and smashes them together into one false statement. "Company X launched feature Y in Q2." The truth? It was Company Z, and it happened in Q4. These slip through because the sentence feels right to a reviewer who isn't a deep domain expert. This is exactly why your review process needs input from SMEs, not just an editor polishing prose.
Temporal errors (outdated facts presented as current)
LLMs have training cutoffs, and they don't naturally tell you when their knowledge is stale. They just give you the last answer they knew. Pricing changes, new regulations, product updates, who has what market share, all of it can show up in your content as a current fact when it's actually 18 months out of date. When you're testing, give the AI a topic where you know the facts have changed recently. Then watch to see if it confidently gives you the old, wrong answer.
Product/feature invention (especially in marketing copy)
For any of us in SaaS, this is the highest-stakes error. The AI writes about your product, or your competitor's, and just invents a capability, a pricing tier, or an integration that doesn't exist. The moment that goes live, it's not just an editing mistake. It's a credibility crisis and maybe even a legal headache. This happens all the time when a platform isn't grounded in your specific, enforced product context.
How do you run a fair, repeatable factual accuracy evaluation across vendors?
Look, vendors are going to show you beautiful, polished demos. That's their job. Your job is to ignore the demo and run a structured test that you control. Before you even touch a platform, you need to ask the hard questions they probably won't bring up themselves.
| Area to Probe | Question to Ask |
|---|---|
| Grounding & RAG | If your knowledge source has no answer, what does the model do? Does it say "I don't know" or just make something up from its general training? |
| Freshness | How do you handle information that changed last month? How does the AI show it's not sure about something recent? |
| Domain Specificity | Our niche is pretty specific. What data or grounding sources do you have that prove you can handle it? |
| Workflow & QA | Show me exactly how a reviewer traces a claim back to its source in your system. What happens if they flag a claim as unverified? |
Build your "ground truth pack" (sources you trust and will enforce)
Before you test anything, get your own house in order. Assemble the set of documents your team will use as the single source of truth for verification. This should include:
- Your official product documentation and feature list.
- 5–10 industry sources you already trust (like analyst reports or key trade publications).
- A list of competitor claims you know for a fact are true or false.
- A few "known false" statements about your industry to see if the AI repeats them.
This little bit of prep work forces you to define what "accurate" means to you and gives your reviewers a consistent reference.
Create a prompt set that mirrors real production (not demos)
Don't test with generic prompts. Test with the kind of content you actually have to get out the door every week. A solid evaluation set should include:
| Prompt Category | Why It Matters |
|---|---|
| Definition/explainer on a core concept in your niche | Tests basic domain knowledge. |
| "Top X tools for [your category]" list | Tests how it handles competitors and whether its info is current. |
| Product-adjacent use case description | A breeding ground for invented features. See if any pop up. |
| Comparison piece (your category vs an adjacent one) | Tests if it understands nuance or just conflates things. |
| Update-sensitive topic (pricing, regulations, market data) | Directly tests freshness and how it handles uncertainty. |
Run the exact same prompts on every platform you're testing. And don't let vendors run the test for you and send you the results. You drive.
Use a scoring rubric your team can apply consistently
You have to score each output at the claim level, not the whole article. One post can have 20 different claims. Grade each one.
- Correct and sourced: The claim is true and has a real, verifiable source. (2 points)
- Correct but unsourced: The claim is true, but there's no attribution. (1 point)
- Uncertain/unverifiable: You can't prove it right or wrong without a research project. (0 points, flag for review)
- Incorrect: The claim is just plain wrong. (−1 point)
- Fabricated source: The citation is fake. (Automatic DQ for that entire output)
Track this in a simple spreadsheet. It will give you a clear factuality percentage for each vendor and each content type.
Set "go/no-go" thresholds by risk level
Not all content is created equal. A mistake in a top-of-funnel blog post is different from a mistake on a pricing page. Set your standards accordingly.
- Top-funnel awareness content: We aim for an 85%+ factuality score. Unsourced-but-correct claims are okay if an editor spot-checks them.
- Comparison and category pages: This needs to be 90%+ accurate. We verify every competitor claim, and there's zero tolerance for fake sources.
- Product-adjacent content: This is our crown jewels. We demand 95%+ accuracy and SME sign-off. Any invented product detail is an automatic disqualification.
These aren't random numbers; they map to where an error does the most damage. The best platforms have a workflow that connects research to briefing to drafting to QA, which helps prevent these checks from falling through the cracks. You want a system that makes accuracy checks consistent, not heroic.
How do you test niche/domain accuracy vs generalist performance?
The "paired test": same task in a broad domain and your niche
Okay, here's a test I love because most teams skip it, and it tells you almost everything you need to know. Take one of your test prompts, like "compare the top three approaches to [topic]," and run it twice. First, use a generic topic anyone could write about (e.g., remote work tools). Second, use a topic that is highly specific to your niche.
Score both outputs with your rubric. The gap between the two scores is the platform's accuracy decay rate in your domain. A platform might get 92% on the generic topic but only 67% on your niche one. That gap tells you the platform is basically guessing when it comes to your space. It means every single draft is going to need a heavy-lift review from your experts, which completely wipes out the time savings you were hoping for.
What to do when your niche has limited public sources
Some of our industries are just tough for AI. If your domain is super narrow, highly regulated, or moving at the speed of light, the public data is probably sparse and outdated. Here's what we've found actually works:
- Feed your own documentation: If a platform supports RAG (retrieval-augmented generation) or custom knowledge bases, you can ground it in your own docs. But you have to test it. Does feeding it your docs actually change the output, or does the AI just ignore it?
- Build an approved source list: Even without a fancy RAG setup, you can give the platform a list of sources you approve of and see if it actually uses them. It's a good signal.
- Accept a higher human review bar: Let's be realistic. If your domain is thin on public data, no AI will be 95% accurate out of the box. For anything domain-specific, you need to plan for a tighter human review loop. Look for platforms that are honest about this and flag uncertainty instead of faking it.
When specialized knowledge approaches matter (and when they don't)
You'll hear the term RAG a lot. It's just a fancy way of saying the AI reads your documents before it writes. It's a huge deal for accuracy. But here's the catch: every vendor will say "we support RAG." That's a claim, not proof. You have to test it. Ask them, "If my source document doesn't have the answer, what does the model do?" A good answer is, "It will tell you that." A bad answer is, "It will use its general knowledge to fill in the blank." That single distinction will make or break your content quality at scale. For top-funnel content, maybe it's fine. For anything about your product, pricing, or regulations, it's a non-starter.
What platform capabilities make factual accuracy easier to maintain at scale?
What "citation-ready" output looks like
Good factual output doesn't just have a bunch of links at the bottom. The claims themselves are scoped to what the sources actually support. You want to see specific claims, attributed to named sources, with appropriate hedges like "as of March 2024" or "according to Gartner's report." Vague phrases like "studies show" or "experts agree" are huge red flags. It's the AI equivalent of mumbling because it doesn't know the real answer.
Confidence scoring and explainability: helpful, but not a substitute
Some platforms will give you a "confidence score" for their claims. These can be useful for helping your human reviewers figure out where to focus their energy. But they are not a substitute for actually checking the facts. A model can be 100% confident and 100% wrong. Treat these scores as a helpful guide for triage, not a green light to publish.
Structured workflows beat ad-hoc prompts for accuracy
I've learned this one over and over. One-off prompts in a chatbot give you lower accuracy than a staged pipeline. When research, briefing, drafting, and QA are separate steps, you catch errors early before they cascade. It feels like more work, but it's faster in the long run, especially when you're producing content at any kind of volume.
Retrieval-augmented grounding (RAG) and source constraints (conceptually)
RAG is a game-changer when it works. It means the AI is forced to base its answers on a set of documents you provide. But as I said, you have to test it. The real value isn't just that the feature exists; it's whether the grounding actually constrains the AI from making things up.
How should a content team operationalize human-in-the-loop verification (without becoming the bottleneck)?
"A human will review it" isn't a plan. It's a prayer. And it's how bad content gets published. If you want a system that works, you need to define the roles and the process.
Define roles: drafter, fact-checker, editor, subject-matter reviewer
These are four different jobs, even if they aren't four different people. On a small team, one person might do several. The key is to be explicit about who is responsible for what.
- Drafter: Runs the AI, designs the prompt, and does a first pass to catch obvious garbage.
- Fact-checker: Verifies specific claims against your ground truth pack. This person is the one scoring the output.
- Editor: Reviews for voice, flow, and strategy. They are not the primary fact-checker. Their job is to trust the fact-checker did theirs.
- Subject-matter reviewer (SME): The expert who signs off on technical or product-heavy content. They are the court of final appeal.
Document this. It seems silly and formal until it saves you from a major public correction.
Create an escalation path for "uncertain or unverified" claims
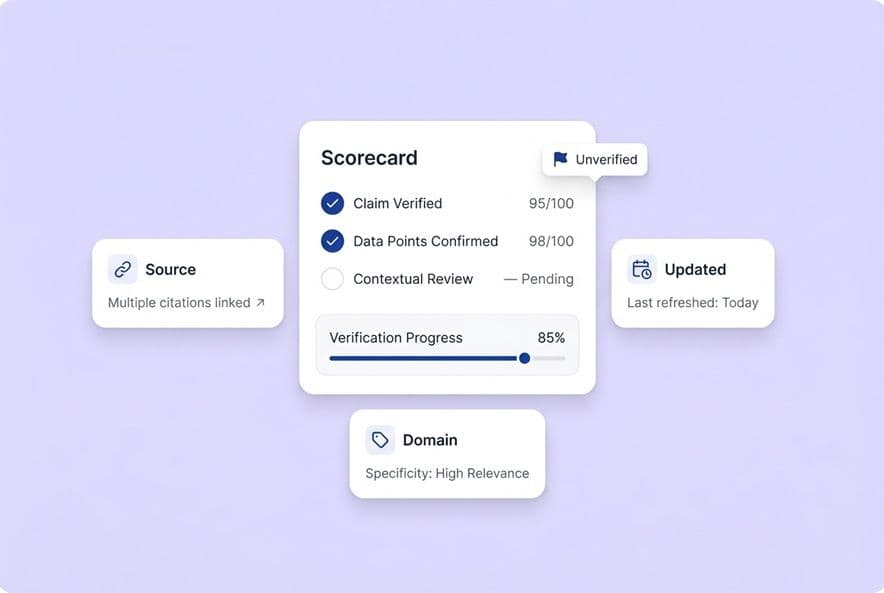
This is where most workflows fall apart. A reviewer finds a claim they can't verify. What happens next? You need a simple rule: any claim that scores a 0 (unverified) either gets a confirmed source or it gets cut. Period. No unverified claims go live.
QA checklists by content type (top-funnel vs comparisons vs product-adjacent)
Consistency comes from checklists, not from people's individual judgment. Keep it simple.
- Top-funnel content: Verify all stats and direct quotes. Flag anything that names a competitor for a second look.
- Comparison/category pages: Independently verify every single claim about a competitor's features and pricing.
- Product-adjacent content: Get mandatory sign-off from an SME. Verify every feature mention against your internal docs.
Build these checklists right into your project management tool. Automating the boring stuff helps your team spend their precious review time on the facts, not the formatting.
How do bias, governance, and accountability fit into factual accuracy?
Bias vs factuality: where they overlap in marketing content
In our world, bias often shows up as a factuality problem. An AI that only ever pulls stats that frame your category in a positive light isn't technically lying, but it's creating a misleading picture. Watch for this. Is it only citing favorable stats? Is it using loaded language? Is it conveniently omitting common objections? These aren't hallucinations, but they create the same erosion of trust.
Lightweight governance for content teams (what to document and enforce)
You don't need to hire a team of lawyers or set up a formal ethics board. You just need a few simple documents to keep everyone on the same page. For teams looking for a starting point, the NIST AI Risk Management Framework offers practical guidance on governing AI systems responsibly.
- Approved source list: The short list of sources you can cite without extra hoops.
- Claim boundary guide: A simple doc outlining what you can and cannot say your product does.
- Error log: When something wrong gets published (and it will), document it. What was it, how did it slip through, and what process are you changing so it doesn't happen again? An error log is the most powerful and underused governance tool there is.
Accountability model: who is responsible when AI ships something wrong?
It's simple: the content lead. The AI is a tool, like a word processor. The human who hits 'publish' is the one who's accountable. The platform's job is to make verification as easy as possible with traceable sources and clear signals. Your team's process is responsible for making sure a human with real accountability signs off before anything sees the light of day.
How does factual accuracy affect SEO and AI answer visibility (AEO) in practice?
Why AI engines favor claim-level, sourceable statements
Here's something I want you to connect. All this work on factual accuracy isn't just about protecting your brand. It's a direct investment in your future SEO, or what people are starting to call AEO (AI engine optimization).
AI answer engines like Perplexity, ChatGPT, and Google's AI overviews love to cite content when they can grab a specific, verifiable claim from a clear source. They don't cite vague, wishy-washy paragraphs. Content built on a foundation of clear, sourced claims is structurally better for this new world.
What to change in your content format to become more "citable"
Here are a few formatting moves that make your content easier for other AIs to cite:
- Answer the question directly in the first sentence of a section.
- Use structured data like tables and comparisons.
- Write tight, scoped definitions and attribute them.
- Use FAQ blocks with direct, factual answers.
- Attribute sources right in the copy ("According to Forrester...").
How to measure progress (without guessing)
Define a set of questions your buyers would realistically ask an AI. Then track how often your content gets cited as a source for those answers. You can do this manually, or you can use tools that are starting to pop up to track this. The point is to connect the dots between "we published accurate, structured content" and "our citation rate for this important topic went up." Without that feedback loop, you're just guessing.
Build your factual accuracy scorecard (and use it on your shortlist)
Okay, you have the playbook. A four-part model for accuracy. A list of the most dangerous hallucinations. A step-by-step plan for running a fair test.
The next move isn't to read another article. It's to do the work.
Take your current shortlist of 2–3 AI content platforms and run this evaluation. Build a simple scorecard in a spreadsheet. Score every output with the same rubric.
What you'll get is a documented, defensible reason to choose one platform over another, based on how it performs under your real-world conditions, not how it looked in a sales demo. That's the difference between an AI investment that scales and one that just creates a hidden debt of rework you'll be paying off for months to come.