You've been there. You type your brand's core use case into ChatGPT, and a competitor pops up. You try Perplexity, and it's a different competitor. So you do what any of us would do: screenshot it, fire it off to your VP, and brace for the inevitable "we need to fix this." Then all eyes turn to you.
The real problem isn't that you're not showing up. It's that you have no system. You don't know why you're not there, where you're not there, or what the hell to do about it. You're armed with screenshots and a sense of dread, but what you need is a measurement program.
I've lived this, and I'm telling you: AI search visibility is real and you can absolutely measure it. But you have to treat AI answers the same way you treat a SERP. That means building a prompt universe, tracking your citations and mentions, benchmarking against the competition, and connecting it all back to real pages and actions. Everything else is just chaos and anecdotes. This is the playbook I wish I'd had for building the real thing.
What does it mean for AI search to "cite" your brand (and what should count as a win)?
Okay, before we start measuring anything, we need to agree on what we're actually counting. I've seen teams tie themselves in knots because they didn't do this first. Saying "we showed up in ChatGPT" can mean three very different things, and if you lump them all together, your reporting will be useless in a couple of months.
Define citation types: linked citation vs unlinked mention vs implied source
Here's the taxonomy we use. It's simple, and it holds up in our dashboards.
Linked citation: This is the one you really want. The holy grail. The AI response includes a visible link to your domain or a specific page. It's verifiable, you can attribute it, and it shows the engine is actively pointing people to your content.
Unlinked brand mention: Your company or product name shows up in the answer, but there isn't a link. This isn't worthless, it has value for brand recall and authority. The AI "knows" you. But it's not sending anyone your way.
Implied source: This one is tricky. The AI uses your unique way of framing a problem, your proprietary method, or even lifts language from your content without naming you. It's almost impossible to count automatically and requires a human to spot. This matters for your content strategy, but it's not a KPI you can put on a chart.
Track all three of these, but report them separately. Please, report them separately.
How to score citation quality: prominence, accuracy, and relevance
Not all citations are created equal, right? A footnote at the end of a long answer is a world away from being called out as the solution.
We score every citation we find on three simple dimensions:
- Prominence: Is your brand cited first, or is it buried? A Tier A citation is right at the top. Tier B is somewhere in the middle, one of a few options. Tier C is basically a footnote.
- Accuracy: Is what the AI says about you actually true? This is a bigger deal than you'd think. We'll get to hallucinations later, but basic fact-checking has to be part of every review.
- Relevance: Is the citation for a prompt your buyers actually use? Getting cited for something totally random is just noise. It doesn't help your business.
The reporting mistake to avoid: mixing citations, mentions, and referrals into one number
This is the most common mistake I see. Teams get excited and report "AI mentions: 47." But that number might be 12 linked citations, 30 brand mentions, and 5 implied sources. It's all mashed into a single number that you can't benchmark, explain, or defend when your boss asks what it means.
You need to report citation rate (linked citations per total prompt runs) and mention rate (brand mentions per total prompt runs) as two separate KPIs. Keep the implied source stuff in a research log for the content team. When someone asks you to justify a budget for this, you need numbers that are solid.
Which AI visibility metrics should you track to prove progress (not just anecdotes)?
When you're starting out, the goal isn't to have every metric under the sun. You just need enough to see a trend, spot a problem, and make a case for your budget.
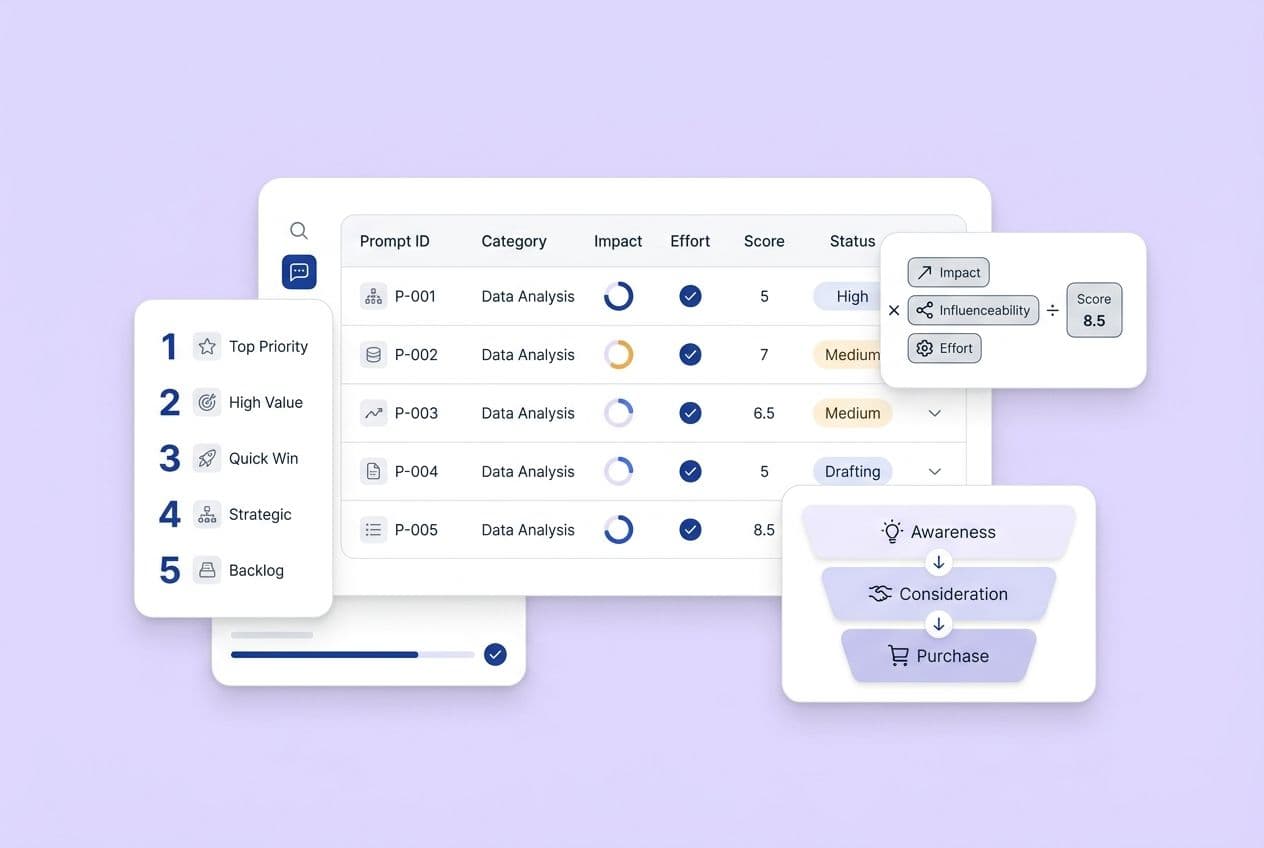
The minimum KPI set: citation rate, mention rate, query coverage, AI share of voice, stability
Here's your starter dashboard. Honestly, this is all you need for the first few months.
- Citation rate: Linked citations ÷ total prompt runs. This is your north star.
- Mention rate: Brand mentions (linked and unlinked) ÷ total prompt runs. This is a great leading indicator. Mentions often show up before you start earning links.
- Query coverage: What percentage of your tracked prompts does your brand appear in at all? This shows your overall reach.
- AI share of voice (AI SOV): Your brand's citations ÷ total citations for your category. This is your main competitive metric.
- Citation stability: If you run a prompt 10 times, how many times do you get cited? If it's 2 out of 10, your stability score is 20%. Low stability means you're in the running, but you haven't really won the spot yet.
Trust me on this one, stability is the metric everyone skips and then regrets. These AI engines are non-deterministic, so the same prompt can give different answers. Stability tells you if you've earned a reliable spot or if you just got lucky.
How to interpret changes: what it means when mentions rise but citations don't (and vice versa)
Mentions are up, citations are flat: The AI knows about you, but it's not using your content as a source. This is usually a content structure problem. Your pages are probably in the training data, but they aren't formatted in a way that's easy for the AI to pull from. Time to work on citeability.
Citations are up, mentions are flat: You're getting linked as a source, but your brand name isn't in the text. This happens when an AI cites a specific page on your blog for an answer without mentioning your company. Check the pages getting linked and make sure your brand is clearly attached to the content.
Both are dropping: This is when you check for a few things. Did a model update change the game? Did a competitor just publish a monster piece of content? Or have your prompts drifted away from what your buyers actually ask?
When (and when not) to include sentiment analysis in your measurement
Sentiment analysis is useful, but only in a few cases. It's worth tracking if you're worried about how your brand story is being told (especially after a PR crisis), if you're in a category where AIs compare you to competitors, or if you're getting hit with negative hallucinations about your product.
For everyone else, it's probably not worth the effort when you're just starting. Get your citation rate and AI SOV baselines locked in first. You can always add sentiment later.
How do you build a prompt library that matches real buyer behavior?
Let me be very clear about this: your SEO keyword list is not your prompt library. Keywords are just fragments. Your buyers ask AI engines full questions, and the way they phrase those questions completely changes the answers.
Start with prompt categories that map to the buyer journey (and pick your "first 25")
Don't try to boil the ocean. I've seen teams try to track 200 prompts from day one, and they burn out in a month. Start with 25 high-value prompts spread across three categories.
- Problem prompts (8-10): "How do I [problem your product solves]?" These are your early-stage, awareness-level questions.
- Commercial inquiry prompts (8-10): "What's the best tool for [use case]?" or "Compare [your category] options." This is where AI SOV is won and lost.
- Proof prompts (5-7): "[Your company name] reviews," "Does [your product] work for [specific use case]?" These check if the AI knows you and represents you accurately.
Why 25? It's enough to see patterns but small enough that you can actually run them consistently across platforms without needing a huge budget or a dedicated team.
Turn keywords into prompts without losing intent (examples for SaaS)
This is a simple translation exercise. Take a keyword, and then think about the real question a person would type into ChatGPT.
| SEO Keyword | Buyer Prompt |
|---|---|
| "content marketing automation" | "How do I automate my content marketing without losing brand voice?" |
| "AI citation tracking" | "How can I tell if my brand is showing up in ChatGPT and Perplexity results?" |
| "AI share of voice" | "What tools track how often my brand is cited in AI search answers?" |
The buyer prompt gets you much closer to the user's intent. It also gives you much more realistic AI outputs to analyze.
Prompt hygiene: keeping prompts stable, comparable, and versioned over time
This is the boring, unsexy part that makes all your data trustworthy. If you tweak a prompt's wording, you're not tracking a trend anymore; you're measuring a completely new thing. So, version your prompts. Log any changes you make. If you add or retire a prompt, start a new data series instead of trying to backfill.
How do you run a baseline audit across ChatGPT, Perplexity, Gemini, Claude, and Google AI Mode?
Before you can track your progress, you need a starting point. Here's how to get a baseline without turning it into a month-long research project.
Manual baseline (quick and cheap): what to document so it's not just screenshots
Run your first 25 prompts across each platform. For every single response, log it in a simple spreadsheet: the prompt, the platform, the date, whether your brand appeared (yes/no), citation type (linked/unlinked/none), who else was cited, and a quick prominence score (A/B/C). These six columns are all you need to establish a baseline you can actually defend.
Here's a critical piece of discipline: run each prompt at least 3 times per platform. A single run is too noisy. Three runs will show you whether a citation is a real, reproducible result or just a random fluke.
Tool-based monitoring: what automation should handle (and what still needs humans)
Here's a core principle of our system: let the machines do what they're good at, so humans can do what they're good at.
Automation should handle the repetitive stuff: scheduled prompt runs, logging the raw outputs, pulling out cited domains, and calculating your rate metrics over time.
Humans need to handle the judgment calls: QAing for accuracy (is what the AI said about you even true?), interpreting weird or ambiguous answers, spotting big structural changes in how platforms respond, and making the strategic content decisions based on the data.
You need both. Tools without a human eye will miss major accuracy and hallucination risks. Humans without tools can't possibly run enough prompts to see real trends.
Frequency and sampling: how often to run prompts to detect real movement
When you're starting out, I recommend weekly runs, with 3 samples per prompt on each platform. That gives you 15 data points per prompt every week, which is enough to start seeing trends without drowning yourself in data.
After about 4-6 weeks, you'll have a baseline. You'll be able to see which prompts are stable (you show up consistently) and which are contested (the results are all over the place). You can then ease up on the stable ones and focus your energy on the contested prompts, since that's where the action is.
With DeepSmith's AI Visibility — Prompts, you can get this whole process up and running fast. Define your prompts and you can immediately start tracking your mention and citation rates across all the major platforms. This frees up your team to focus on analyzing the data and taking action, not copy-pasting from ChatGPT all day.
How do you benchmark competitors and measure AI share of voice (without obsessing over single prompts)?
AI share of voice explained (and how it differs from SEO visibility)
In SEO, share of voice involves keyword rankings and search volume. In AI search, it's a bit different. Every prompt either cites you or it doesn't. AI SOV is simply your citation count divided by the total citations for your category across all the prompts you track.
The tricky part is that AI engines don't always tell you what sources they used. You're making inferences from the outputs, not looking at a clean data set.
Citation displacement: how to spot the pages and sources you're losing to
This is what I call "citation displacement." It's when a commercial prompt that should cite you cites a competitor instead. Your job is to play detective. Log the source that got the citation. Was it the competitor's homepage? A specific comparison page? Or a third-party review site?
If you're losing to third-party sites like G2 or analyst reports, it means intermediaries are answering your buyers' questions. If you're losing to competitor pages directly, it means they have content you don't, or their content is just structured better for AI extraction.
What to evaluate in tools/vendors (coverage, transparency, refresh, support)
When you look at AI visibility tools, ask the hard questions. Which platforms do they actually pull data from? How do they handle the randomness of prompts (do they run multiple samples)? How often does the data refresh? Do they break down citation types, or just give you a vanity "mentions" number? The answers will tell you if you're buying a real measurement system or just a pretty dashboard.
DeepSmith's AI Visibility — Competitors automates this for you. It shows you which competitor pages are getting citations and even monitors their sitemaps. When a competitor publishes a new page that starts winning citations, you'll see it. That's intelligence you can use to brief your own content team.
How do you attribute AI citations back to specific pages—and decide what to update first?
Okay, this is the part that matters most. This is where all that tracking turns into actual work you can assign to your team. Knowing your citation rate is interesting. Knowing which page is winning or losing is what lets you make smart content decisions.
Mapping prompts → cited domains → specific URLs (your site vs third-party sources)
When an AI cites you, grab the specific URL if you can see it. If it's just an unlinked mention, try running the same prompt in a platform like Perplexity that shows its sources. You can often figure out which page the AI is likely drawing from.
Start building a source map. For each group of prompts, list the pages that are getting cited, both yours and your competitors'. You'll spot patterns fast. Problem-stage prompts might hit your blog, while commercial prompts might go to your homepage or a comparison page. This map shows you what's working and where you have content gaps.
Source-gap analysis: when you need better on-site pages vs third-party coverage
Sometimes, you just don't have a page that answers the prompt. The fix is pretty obvious: create one. But what if you have a great page on the topic, and the AI is citing a third-party review site instead? That's a different problem. It might mean your content isn't structured for easy extraction, or the third-party site has stronger authority signals.
If it's an on-site gap, create or update a page. If it's an authority gap, you might need to think about PR, partnerships, or using structured data to boost your brand's presence on those other platforms.
Prioritization framework: update the pages that (1) already get cited, (2) are close to being cited, (3) are money prompts
Don't try to fix everything at once. Here's how I prioritize this, and I suggest you do the same.
- Pages already earning citations: Double down on them. Strengthen them with definition blocks, comparison tables, and clear, attributable claims. A page that wins 3 prompts can be tuned to win 10.
- Pages appearing in AI responses without citations: These pages are "close." The AI knows about them but isn't linking. This is often a simple formatting or extraction issue you can fix.
- Money prompts with zero brand presence: These are your big commercial prompts where competitors are cleaning up. Winning even one of these can have a huge impact.
DeepSmith's AI Visibility — Pages makes this whole process data-driven. It shows you exactly which of your pages are earning citations, how they're trending, and what their share of your brand's AI visibility is. This lets you focus your team on the work that will actually move the needle, instead of just guessing.
What content structures and claim formats make AI engines more likely to cite you?
Most articles about AI visibility stop before they get to this part, which is crazy to me. The tracking tells you what's happening. Your content structure determines why. Here's what we've found actually makes a page easy for an AI to cite.
Write for extraction: definition blocks, scoped claims, and attributable sentences
AIs are lazy. They look for clean, self-contained answers. A long, meandering paragraph is hard to pull from. A simple definition block is a piece of cake.
Before: "Content marketing has evolved significantly, and many companies are now considering AI citation tracking as part of their strategy, which involves looking at how often AI platforms reference your brand."
After: "AI citation tracking is the practice of measuring how often and where AI search platforms reference your brand when responding to buyer queries. It's tracked per prompt, per platform, and separated into linked citations, unlinked mentions, and implied sources."
See the difference? The "after" version is a Lego brick the AI can just pick up and use. Try to write all your key claims this way.
Use structured comparisons and tables (and what to compare to earn citations)
AI models love tables. When a buyer asks for a comparison, the AI will often just lift a table directly from a page. So, build tables that compare things your buyers actually care about: your product vs. the old way, your product vs. a competitor, or different use cases for your product.
Just make sure your table cells contain complete thoughts, not just a word or two. "Higher accuracy" is useless. "Tracks citation rate per platform with 3x sampling for statistical reliability" is an extractable claim.
Entity + schema basics: what "machine readable" means in practice
You don't have to be a developer for this. Using FAQ schema on your FAQ pages, HowTo schema on tutorials, and being consistent with your brand and product names across your site helps AI engines understand who you are. If you're on WordPress or Webflow, there are plugins for this. The content team's job is just to make sure the content itself is clean.
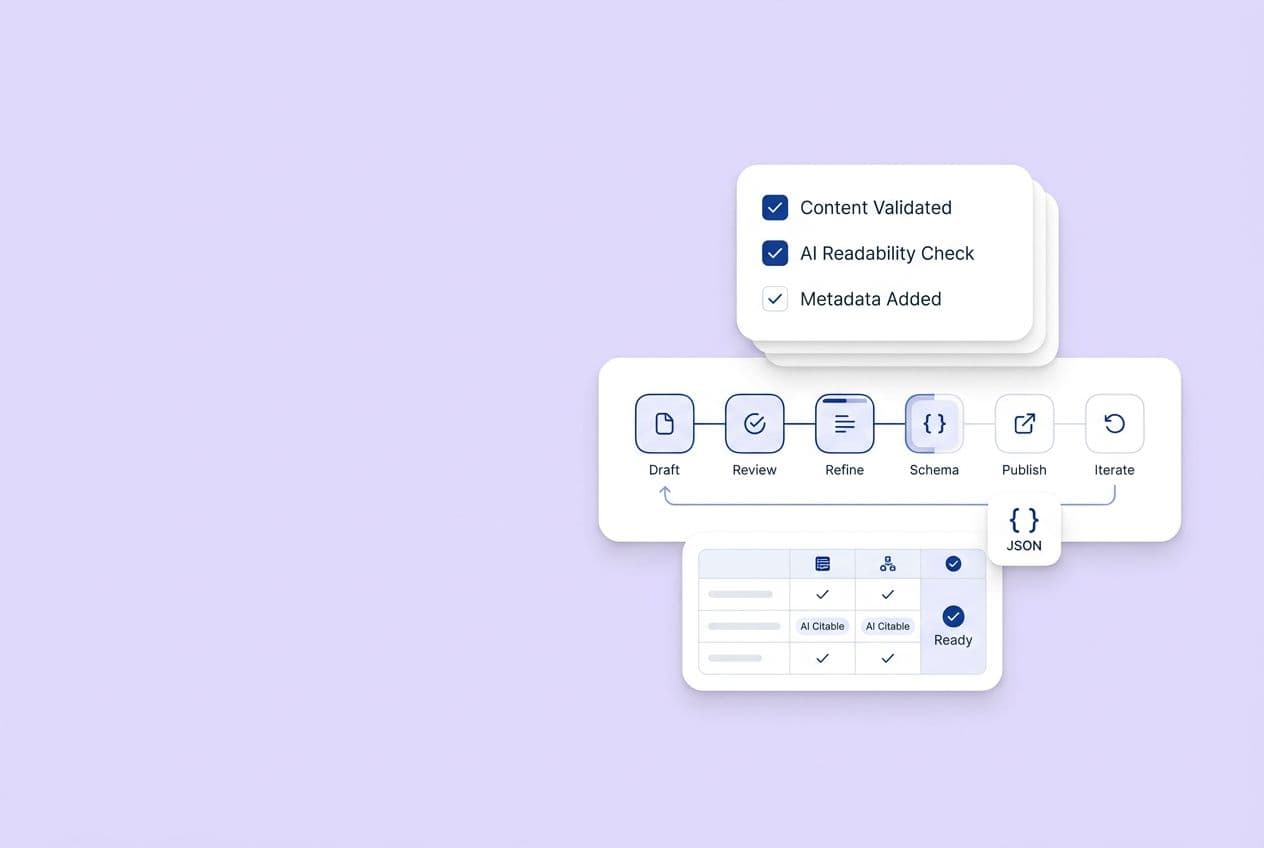
"Citeability QA checklist" before you publish updates
Before you hit "publish" on any page you've optimized, run it through this quick check:
- Does the page open with a sharp, clear definition of its main topic?
- Is there at least one table or structured list with full-sentence cells?
- Are your key claims written as standalone, attributable sentences?
- Are your brand and product names present in a natural way (not stuffed in)?
- Does the page have FAQ schema if there's a Q&A section?
- Are there internal links to other relevant pages to build up your brand authority?
How do you detect and correct hallucinated or false AI attributions about your brand?
AI engines sometimes make things up. They get your pricing wrong, invent features, or misstate facts about your company. This happens. Don't freak out, but don't ignore it either. You need a process.
What to log when you find a hallucination (prompt, engine, output, date, claim)
We keep a simple "hallucination log." It sounds like a lot, but it takes five seconds and helps you spot patterns. The log has five columns: the prompt, the platform, the date, the false claim (copy-paste it), and what type of error it is (wrong fact, wrong attribution, etc.). If you see the same lie popping up everywhere, it probably comes from a single bad source in the training data that you need to counter.
Corrective actions that actually help: on-site clarification, authoritative citations, consistent phrasing
You can't just email OpenAI and tell them to fix it. What you can do is publish clear, authoritative content on your own site that directly contradicts the false claim. Then, try to get that same correct information reflected in third-party sources like press mentions or reviews.
And be consistent. If you describe your product one way on your homepage, another way in your docs, and a third way in a press release, you're just confusing the model. Standardize your key claims everywhere.
Monitoring for recurrence and stability after fixes
Once you've published a correction, keep tracking the relevant prompts for the next 4-6 weeks. Is the hallucination showing up less often? This is where your stability metric is so valuable. It's the only way to know if your fix actually worked.
How to integrate AI citation tracking into your existing SEO + analytics reporting (and justify ROI)
Where AI visibility fits in your dashboard: prompts, pages, topics, pipeline outcomes
The best way to do this is to map your AI visibility data to your existing content system. Your SEO topic clusters become your AI prompt categories. Your top SEO pages become the first pages you track for citations. You can even add an AI visibility layer to your pipeline model to see which AI-cited pages are driving traffic and conversions.
You don't need a whole new dashboard that no one looks at. You just need a new section in the dashboard your team already uses.
Handling regional and multi-language AI visibility
Models aren't the same everywhere. An English prompt for a US buyer will get different results than the same prompt in German for a buyer in Germany. If you sell in multiple markets, you have to segment your measurement. Track prompts in the local language, use geo-specific settings in your tools, and keep separate benchmarks for each market. Lumping it all together will hide major problems and opportunities.
Cost scaling: the minimum viable monitoring setup vs when to expand
Minimum viable: Start with 25 prompts on 5 platforms, run them weekly, and have one person review the outputs. This is totally manageable for a small team and will give you enough data to spot trends in 6-8 weeks.
Expand when: Your citation rate starts moving and you need to know why. You have three or more competitors you need to track. Or, leadership is asking for quarterly reports and you need more data to make them meaningful.
Don't scale up your prompt list until you've mastered the workflow for your first 25. More data before you have a process is just more noise.
A 30-day implementation plan you can run with a lean team
Week 1: Define your citation types (linked/unlinked/implied). Pick your first 25 prompts. Run your manual baseline across all five platforms.
Week 2: Set up your KPI tracker (citation rate, mention rate, etc.). Find your top 5 priority pages based on what you saw in the baseline. Run those pages through the citeability checklist.
Week 3: Publish the updated versions of your priority pages. Log the baseline citation counts for your competitors on your commercial prompts.
Week 4: Run your second batch of prompts. Compare everything to your Week 1 baseline. Now you have your first report: citation rate, mention rate, AI SOV vs. your top competitors, and which of your pages are earning citations.
In DeepSmith, this whole workflow is connected. AI Visibility — Prompts tracks your prompts, AI Visibility — Pages shows you which pages are winning, and AI Visibility — Competitors benchmarks you against everyone else. When the data tells you what to do, Content Studio helps you create citation-ready content with all the right formatting built-in. It all rolls up into the AI Visibility — Overview dashboard, which gives leadership a single, clear view of how you're doing.
Build your AI citation measurement system (and keep it running)
The teams I see winning in AI visibility aren't the ones who search ChatGPT the most. They're the ones who built a system. They defined a prompt universe, tracked it consistently, tied citations back to specific pages, and used that data to create better content faster than their competitors.
It all starts with the framework you just read. It gets easier when you have the right tools to handle the operational grind so your team can focus on making smart decisions.
Start small. Pick your 25 prompts this week. Run a baseline. Choose your priority pages. And build from there.
If you want to run this system without having to glue a bunch of spreadsheets together, DeepSmith's AI Visibility suite can help. It handles the prompt tracking, page attribution, and competitive benchmarking, while our Content Studio closes the loop from measurement to published, citation-ready content.