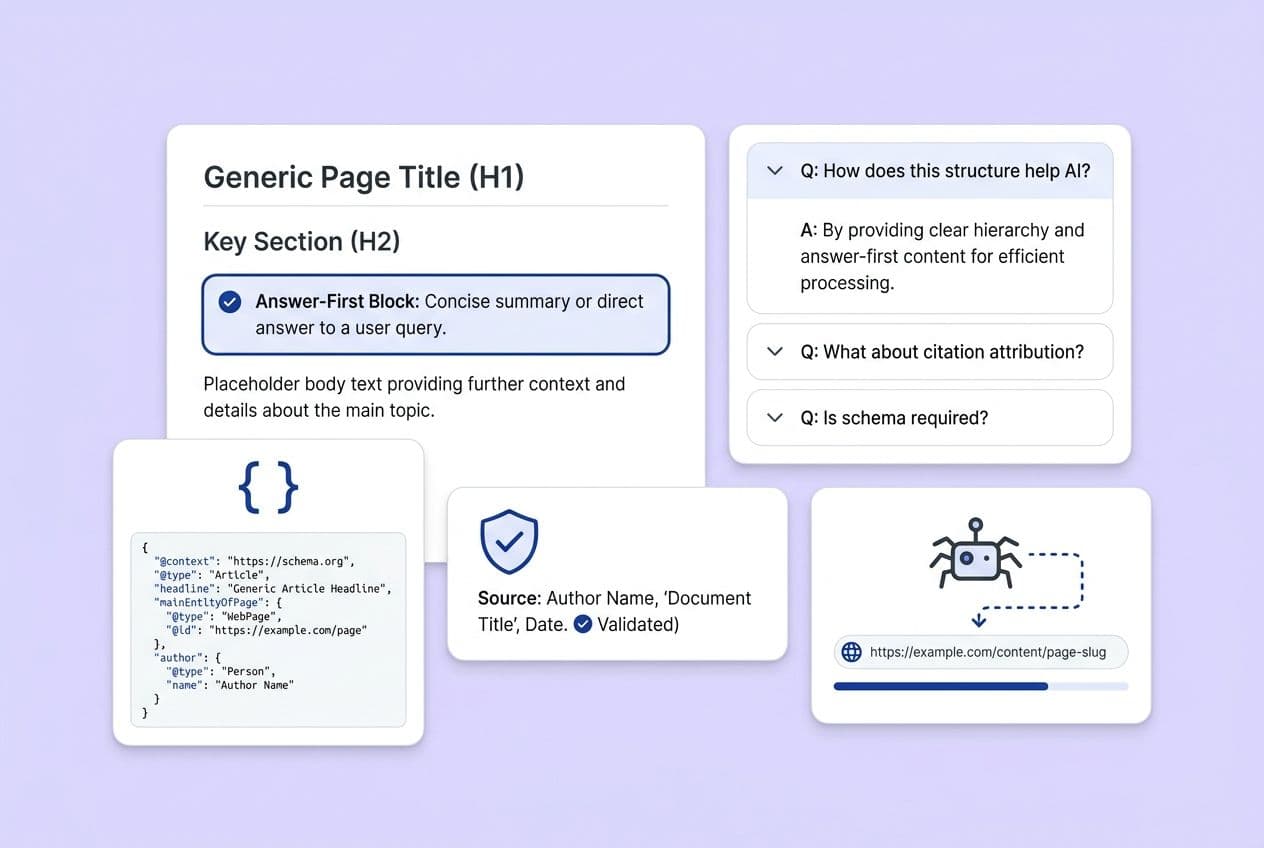
AI citations come down to four things: how easy your content is to extract (clean structure), interpret (schema and entities), trust (proof and authority), and access (crawlability and clean HTML). The good news is you can improve all four with specific page elements, no new tech stack required. The fastest way to see results is to start with answer-first section openings, FAQPage schema, Organization and Person entity markup, attributed proof blocks, and verified crawl access for AI bots.
If you're reading this, you probably rank for a bunch of things. And yet, you still don't show up when someone asks ChatGPT or Perplexity a question you should own. Your CEO has started forwarding you screenshots of competitors getting cited. You’ve spent an afternoon manually searching your core use case in three different AI tools, only to find a mix of irrelevant results and competitor names. Now you’re being asked, “What’s our AI search strategy?” and you don’t have a clean answer.
I’ve been there. That gap between ranking in search and getting cited in AI feels personal. But it’s fixable. It’s almost always a page-element problem, not a content strategy problem.
Here’s the plan: I’m going to give you a 5-change priority list you can start on this week. Then we'll dive deep into each page element (structure, schema, technical hygiene, and trust signals). And finally, I’ll share a lightweight tracking workflow so you know what to do next, not just what to do once.
What Does "Getting Cited by AI Search" Actually Mean, and Why It's Not the Same as Ranking?
AI citation happens when a model quotes or links to your page as the source for a specific claim. This is the goal. It’s different from an AI mention (your brand name appears in an answer without a link) or an AI summary (the model paraphrases your topic without crediting you). Citations are what drive clickthroughs, signal authority, and compound over time as models retrain on what they’ve already surfaced.
Here's the key distinction you need to get: AI engines don't read your article and decide it's "good." They retrieve discrete passage blocks, usually 50 to 200 words long, that directly answer a query. If your page contains that perfect, bite-sized passage, structured in a way the model can extract cleanly, you get cited. If you bury the answer in three paragraphs of context-setting, the model just moves on to a source that doesn’t make it work so hard.
And yes, the models are all different. ChatGPT, Gemini, Perplexity, Claude, and Google’s AI Overviews each weigh sources differently. Some favor recency, some favor domain authority, and some favor structured data. A page that gets cited by Perplexity won't automatically get cited by Gemini. So please, avoid any strategy that promises "optimize once, get cited everywhere." The only practical approach is to optimize your page so any individual section can stand alone as a citable answer, no matter which model comes knocking.
What AI Systems Look for When Choosing Sources
AI systems are basically running a quick background check on your content using four criteria:
- Retrieval/access: Can the page be crawled? Is the content actually in the HTML, or is it locked behind some JavaScript that won't render?
- Comprehension: Is the content structured so a model can parse which text answers which question?
- Confidence: Is the claim backed by named sources, data, or verifiable evidence?
- Recency: Does the page show signs of being fresh (updated dates, current examples, recent data)?
You can have the best content in the world, but if you miss one of these, you’re invisible.
The Passage-Level Mindset Editors Need
Treat each H2 section like a mini landing page. It needs to open with a one or two-sentence direct answer, and then support that answer with evidence and context. A model scanning your page for "what schema markup helps AI citations" has to find the answer in the first two sentences of that section, not after two paragraphs of historical background.
I used to write those big, winding intros, thinking I was setting the stage. All I was doing was making the model's job harder and getting skipped over for a competitor who just gave the answer. Vague section intros like "There are many factors to consider when thinking about..." are a signal for models to move on. They aren't skimming; they're pattern-matching for answer-shaped content. Your job is to give them the answer shape.
What Are the 5 Highest-Impact Page Elements to Fix First If You Want More AI Citations?
The fastest wins aren't about rewriting your entire blog. They're about making targeted changes to the elements that directly influence whether a model decides to retrieve, trust, and quote your content. Here’s the priority list I give every team, in order of impact-to-effort.
-
Answer-first section openings + question-based H2 headers
- What to change: Rewrite every H2 to mirror a real buyer query. Then, open each section with a direct, one-to-two-sentence answer.
- Why it helps: Models pattern-match on section openings. This answer-first structure is the single biggest signal for extractability.
- Common pitfall: Writing H2s as noun phrases ("Schema Best Practices") instead of questions ("Which schema types help AI citations?").
- Validate: Read each section opener in isolation. If it doesn't answer a question, rewrite it.
-
FAQ block on key pages + FAQPage schema
- What to change: Add a 5–8 question FAQ to your highest-intent pages. Implement FAQPage schema that exactly mirrors the visible Q&A on the page.
- Why it helps: FAQ blocks are pre-formatted answer units. The schema explicitly tells parsers, "Hey, this page is designed to answer questions."
- Common pitfall: The schema Q&A doesn't match the visible text. This is a huge red flag for both models and validators.
- Validate: Use Google's Rich Results Test to confirm your FAQPage markup renders cleanly.
-
Organization + Person schema completeness (including
sameAs)- What to change: Ensure your site-wide Organization schema includes your logo, founding date, and
sameAslinks to LinkedIn, Twitter/X, Crunchbase, and G2. Add Person schema withsameAsfor your authors. - Why it helps: This is about entity resolution. Models need to confirm you are who you say you are before they'll cite you as an authoritative source.
- Common pitfall: Incomplete Organization schema with missing
urlorsameAsfields. It sends a weak entity signal. - Validate: Use the Schema Markup Validator at schema.org.
- What to change: Ensure your site-wide Organization schema includes your logo, founding date, and
-
Factual density + named-source attribution
- What to change: Add at least one concrete, attributed data point every 150–200 words. Name the source right in the sentence ("according to [Source]") instead of using vague references.
- Why it helps: Models give more weight to pages with verifiable, attributed claims when they're assessing confidence.
- Common pitfall: Citing stats without attribution ("studies show..."). This adds zero trust.
- Validate: Read through each section. If you can't name the source of every claim, you have a proof gap.
-
Crawl access + clean, fast pages
- What to change: Confirm key AI crawlers aren't blocked in your robots.txt file. Keep pages under a 3-second load time and the HTML under about 100KB.
- Why it helps: Access is everything. A perfectly optimized page that can't be crawled will earn exactly zero citations.
- Common pitfall: A blanket
Disallow: /for non-Google bots that someone added "temporarily" three years ago. I've seen it happen. - Validate: A quick robots.txt audit and a run through PageSpeed Insights.
Treat these as probabilistic improvements, not guarantees. Implement them, track the changes, and keep iterating.
Impact × Effort Triage Table
| Change | Lift Potential | Editor-Owned? | Needs Dev? | How to Validate | Common Failure Mode |
|---|---|---|---|---|---|
| Answer-first openings + question H2s | High | Yes | No | Read section opener in isolation | Opening answers the topic, not the question |
| FAQ block + FAQPage schema | High | Partially | For schema injection | Google Rich Results Test | Schema Q&A doesn't match visible text |
| Organization + Person schema | Medium-High | No | Yes (initial setup) | Schema Markup Validator | Missing sameAs or url fields |
| Factual density + attribution | Medium | Yes | No | Proof-block audit per section | Claims without named sources |
| Crawl access + page hygiene | High (foundational) | No | Yes | robots.txt audit + PageSpeed | AI crawlers blocked by legacy rules |
How Should You Structure Your Content So AI Can Extract (and Cite) It Cleanly?
Write in self-contained, answer-first units of 60–180 words, with one question per unit. This lets a model lift any section without losing its meaning. The funny thing is, this isn't about writing for robots. It’s the same thing that makes content better for humans who scan before they commit to reading.
The answer-first rule is simple: the first 1–2 sentences of every H2 section must directly answer the question the heading poses. Everything after that (context, evidence, caveats) just supports the answer. Don't build up to it. State it.
Header hierarchy matters more than most of us realize:
- H1 once, for the main page topic.
- H2s as distinct buyer questions, with each section being a citable unit.
- H3s as supporting sub-questions that mirror real search or chat queries.
Citation hooks you can add to any section:
- Definition in the first ~200 words: Define the page's main topic and any major concept when it's first introduced.
- Numbered frameworks: Models love extracting steps, checklists, and decision sequences.
- Comparison tables: Use these wherever choices or trade-offs exist.
- Explicit constraints: Phrases like "This works best when X" and "This won't help if Y" signal nuance and make a passage more trustworthy.
Aim for at least one concrete, attributed data point every 150–200 words. This isn't just padding; it's the evidence layer that makes a passage citable instead of just readable.
And please, avoid these "robotic GEO" mistakes that kill extractability:
- Generic intros that delay the answer by two paragraphs.
- Repeating the same claim three different ways in one section. It just dilutes density and confuses the model.
- Keyword-stuffed sentences that break the natural answer pattern a model is looking for.
The "Citable Paragraph" Template (Copy-Ready)
When you have a key claim you want a model to quote, use this structure:
Sentence 1 (Direct claim): State the answer or finding directly. No warm-up.
Sentence 2 (Condition/context): "This holds true when the page uses semantic HTML and the section opens with the direct answer. If either is missing, extraction reliability drops."
Sentences 3–4 (Evidence + implication): Reference a named source, a documented pattern, or a concrete example. Then, state what this means for the reader's decision or next action.
This four-sentence block is the atom of a citation-ready page. You don't need every paragraph to follow it, but the main claim in each section should.
When to Use Lists vs. Tables, and Why Tables Get Cited
Use lists for steps and requirements; use tables for comparisons and trade-offs. The distinction matters because models parse them differently.
Lists are great when the items are sequential or parallel but don't need to be compared against each other. Tables are for when you're comparing multiple options across consistent dimensions, like schema types, bot names, or tool trade-offs.
Tables are disproportionately citable because they are pre-structured. A model can extract a single row, and the column headers give it all the context it needs without parsing the surrounding paragraphs. If you're currently describing comparisons in prose, converting them to tables is one of the fastest structural wins you can make.
Which Schema Markup Types Most Reliably Increase AI Citations, and What Implementation Mistakes Kill the Upside?
Schema helps AI systems figure out who you are and what your page is about. A small set of types, implemented cleanly, does most of the work. The goal isn't to use every possible schema type; it's to give models the structured signals they need to confidently identify you, understand your content, and trust it.
I've seen so many teams get this wrong. A client couldn't figure out why their authority wasn't being recognized by the models. Turns out, their Organization schema was missing sameAs links. The models literally couldn't connect their website to their well-known LinkedIn and G2 profiles. It was a ten-minute fix that changed everything.
Use JSON-LD consistently. It's what Google recommends, it’s cleanly separated from your HTML, and it's much easier to validate and maintain than microdata.
FAQPage schema tends to be incredibly effective because FAQ content is already in question-answer pairs, the exact structure models use. The schema just labels that structure explicitly. This combination (structured content + explicit markup) reduces the interpretation work a model has to do, which makes extraction more likely. It's not a guarantee, but it's a powerful signal.
Schema Type → Best Page Candidates → Editor Checklist
| Schema Type | Use It When | Minimum Fields to Be Complete | Don't Do This | How to Validate |
|---|---|---|---|---|
| Organization | All pages (site-wide) | name, url, logo, sameAs | Leave sameAs empty or link to dead profiles | Schema Markup Validator |
| Person | Author bio pages, bylined articles | name, jobTitle, url, sameAs | Generic "Staff Writer" with no external profile | Rich Results Test |
| Article / BlogPosting | Blog posts, guides, opinion pieces | headline, author, datePublished, dateModified | Omit dateModified. It kills your recency signals. | Rich Results Test |
| FAQPage | Any page with a visible FAQ block | Each Question and acceptedAnswer must match visible text exactly | Putting FAQPage on pages with no visible FAQ | Google Rich Results Test |
| Product / Service | Product pages, feature pages | name, description, offers or provider | Using Product schema on a blog post | Schema Markup Validator |
| AggregateRating | Pages with genuine review data | ratingValue, reviewCount, bestRating | Fabricating or inflating review counts | Rich Results Test + manual spot-check |
FAQ Content ≠ FAQPage Schema: How to Keep Them Aligned
The visible FAQ on your page and the FAQPage schema must match exactly. This is the most common mistake I see, and it can completely neutralize the benefit.
When your schema includes a question and answer that doesn't appear in the rendered HTML, or even appears with slightly different wording, validators flag it as a mismatch. More importantly, models checking the rendered content against the markup will get confused and likely deprioritize the page.
Keep your FAQ answers concise (2–4 sentences) and make sure they add new clarity. If your FAQ answer is just a reworded version of a paragraph three sections up, cut it or rewrite it.
What Technical Page Hygiene Issues Silently Block AI Citations (Even When the Content Is Good)?
If a model can't reliably crawl and parse your page, the quality of your content is irrelevant. Technical hygiene isn't the sexy part of this work, but it’s the foundation for everything else.
AI crawler access: Check your robots.txt file and confirm you're not blocking major AI crawlers. The main ones to know are GPTBot (OpenAI), Google-Extended (Google AI/Gemini), PerplexityBot, ClaudeBot (Anthropic), and CCBot (Common Crawl). I once audited a client's site and found a blanket Disallow rule someone had added "temporarily" three years prior. They were invisible to every AI crawler because of one forgotten line of code. This is a policy decision as much as a technical one, so talk to your legal or security team if your content is sensitive.
Page speed: Keep your load time under 3 seconds. Slow pages get lower crawl priority and create a bad user experience, which just compounds visibility problems. PageSpeed Insights gives you a free, actionable baseline.
Semantic HTML: Use <article>, <section>, and logical heading hierarchies. Avoid burying critical text behind JavaScript. If the body of your page only appears after JS executes, many crawlers (including some AI bots) simply won't see it. When in doubt, check the cached or text-only version of your page.
HTML bloat and crawl efficiency:
- Target a text-to-HTML ratio of at least 25%. Your visible content should make up a quarter of the document's total weight.
- Keep your HTML document size under 100KB where possible.
- Move inline CSS and JavaScript to external files. All that inline noise just obscures your content.
Media elements: Use lazy-loading responsibly, but don't lazy-load your primary above-the-fold content. And make sure your body text doesn't depend on a script to render.
How Do Internal Links, Proof Signals, and Off-Page Authority Influence Whether AI Trusts Your Page Enough to Cite It?
AI citations are about confidence as much as extraction. A model needs to trust that your page is a reliable source before it will link back to it. Your internal link structure, proof signals, and third-party authority all build that confidence.
Internal linking: the under-discussed citation signal
Internal links do three things that matter here: they help crawlers find your pages, they signal topical relationships (a page that links to and gets links from related pages looks like an authoritative cluster), and they provide context that helps models understand what a page is about.
Here's a quick internal link audit you can run this week:
- Find pages with zero internal links pointing to them. These are orphaned pages, and crawlers might miss them entirely.
- Find pages with zero outbound internal links. They aren't participating in your topical network.
- Check your anchor text consistency. If you link to the same page with five different phrases, you're diluting the topical signal.
Link like a librarian: link to your definitions pages when you introduce a term, link to comparisons when presenting options, and link to implementation docs when suggesting next steps. Every link should help a reader (and a crawler) know where to go next.
Proof signals: the credibility layer
You need named attribution for every stat, benchmark, or claim. If you're citing data, name the study or organization in the sentence. If you're using an expert's perspective, attribute it to a real, findable person.
A simple proof block you can paste into any section:
Claim: State the finding or position directly. Evidence: Name the source: "According to [Organization/Study], [specific data point]." Implication: What this means for the reader's decision. Limitation: "This applies when X; if Y is true, the picture changes."
That limitation line is more important than it looks. Pages that acknowledge conditions and edge cases read as more credible, both to humans and to models assessing source quality.
Off-page authority: the corroboration layer
Third-party mentions and reviews matter, especially for models like Perplexity that pull heavily from them. The practical actions here are simple: keep your G2, Capterra, and LinkedIn profiles complete and active. Earn relevant press mentions and bylines in industry publications. Just avoid any sketchy tactics that manufacture fake reviews. The short-term gain isn't worth the long-term brand trust cost.
How Do You Set Up a Lightweight AI Citation Tracking Workflow That Tells You What to Fix Next?
You have to track AI citations the same way you track SEO. You define a set of prompts, run baseline checks across the major models, map the citations back to your pages, and run a monthly update loop. Without this, you're just optimizing blind. You'll never know if your changes are actually working.
Step 1: Define 20–50 buyer prompts. Cover four types: category queries ("best [category] tools for [use case]"), comparison queries ("X vs Y"), implementation queries ("how to do Z"), and definition queries ("what is [term]").
Step 2: Run baseline checks on a schedule. Test each prompt across ChatGPT, Gemini, Perplexity, Claude, and Google AI Overviews. Record which sources get cited and whether your pages appear. A weekly or biweekly cadence is plenty.
Step 3: Map cited sources to page types. Which of your pages are getting cited? Guides? Glossary entries? FAQ pages? This tells you which formats the models are currently rewarding in your space.
Step 4: Build an "AI citation backlog" with three categories:
- Update candidates: Pages already ranking in organic search but not getting cited. These are your best bet for a quick win.
- New pages: Question gaps where you have no coverage at all.
- Schema/FAQ upgrades: Pages that have the right content but lack the structural signals.
Step 5: Re-test and document the changes. After updating a page, re-run the relevant prompts a few weeks later and record what happened. This whole process is iterative. What works today might need a refresh in six months.
This is the part where tracking becomes a pain, which is honestly why my team and I built the AI Visibility module in DeepSmith. It tracks your brand's citation rate per prompt across all the major models and gives you page-level attribution. It turns hours of manual prompt testing into a trackable dashboard.
The Minimum Viable "AI Visibility Dashboard" (Fields List)
If you're starting manually in a spreadsheet, just track these fields:
- Prompt: The exact query you tested.
- Platform: ChatGPT / Gemini / Perplexity / etc.
- Date: When you ran the test.
- Top cited sources: URLs of pages the model cited.
- Were you cited?: Yes / No / Mentioned without citation.
- Cited page URL: Which of your pages appeared.
- Page element hypothesis: Which element you think drove or blocked the citation.
- Action taken: What you updated after the test.
- Result: What changed on the next test.
This is enough to start seeing patterns and prioritizing your work.
How Do You Turn These Page Elements Into a Repeatable Content System (So It Doesn't Die After One Sprint)?
The difference between teams that get sustained citation lift and teams that just run one optimization sprint and then stall is standardization. These page-element fixes only work when they're baked into your templates and your QA process, not when they're done retroactively.
Consistency is the real competitive advantage. A competitor who ships citation-ready content every week will always outpace one who optimizes fifty pages once and then stops.
Build a "citation-ready" content template with these requirements:
- H2 headers must be phrased as questions.
- Each section must open with a direct, 1–2 sentence answer.
- Minimum one attributed proof point (stat, named source, or expert) per H2.
- Every piece with 5+ H2s must include a FAQ block.
- Comparison tables are required wherever choices or trade-offs exist.
- Author bio with credentials and a
sameAslink is required on all bylined content.
Add a 10-point editorial QA checklist:
- H1 matches the target query intent.
- The first paragraph answers the core question directly.
- Every H2 is a question.
- Each section opens with a direct answer.
- At least one attributed proof point per section.
- FAQ block is present (if applicable) and matches the schema.
- Internal links are present (minimum 2–3 per article).
- Author bio is complete with an external profile link.
- Schema type matches page intent; FAQPage schema is present if an FAQ exists.
- No vague intros, repeated claims, or unattributed stats.
For existing content, start with high-intent pages that already rank in organic search but aren't getting cited. The traffic signal confirms the topic matters; the citation gap means the structure or schema is missing.
This is the kind of repeatable workflow we built for ourselves at DeepSmith with our Content Studio. Structure, internal links, and metadata are part of the writing pipeline, not a review checklist you apply after the fact. It’s the difference between reducing rework and eliminating it.
How Do You Learn from Competitor Citations Without Copying Them (and Without Turning Your Blog Into Generic AI Sludge)?
Competitor pages that earn AI citations tell you which questions models are rewarding and which formats they favor. They don't tell you what to copy. The insight is in the pattern, not the specific content.
When a competitor consistently gets cited for a query you should own, look at four things:
- The question it answered: Is there a gap in your coverage, or do you cover it less directly?
- The structure it used: Was it a table, numbered steps, a definition, or an FAQ block?
- The proof types present: Did they use named stats, expert quotes, or original research?
- Freshness signals: Are there recent update dates, current examples, or timely data?
Extract the pattern. Then, go produce a better, more specific version with your own evidence, examples, and point of view.
What not to do:
- Don't copy the structure verbatim without adding your own data or perspective. You'll just create a weaker version of something that already exists.
- Don't just reword their key points. Models can often detect source material, and good editors can always tell.
Remix checklist:
- Add a clearer stance than the competitor took (they probably hedged; you don't have to).
- Add specific examples from your domain, your customers, or your own use cases.
- Add the constraints and edge cases the competitor glossed over.
- Write a tighter FAQ with more directly actionable answers.
- Update any data points that are older than a year or so.
We built the AI Visibility — Competitors feature in DeepSmith to automate this. It monitors which competitor pages are winning citations for your tracked prompts and turns those insights into original content ideas. It's not a copy-paste tool; it's a structured brief built around the gap you identified.
The goal isn't to out-optimize your competitors. It's to out-answer them with better structure, a sharper stance, and tighter proof. That's what earns citations.


