So, you searched your brand's core use case in ChatGPT last week. A competitor showed up. You didn't. Now leadership is asking about your "AI search strategy," and you're holding a list of 15 things you've read you're supposed to do (structured data, E-E-A-T, backlinks, author bios, PR mentions) with zero way to decide which one to touch first.
I've been there. That's the actual problem, isn't it? Not a lack of information, but a lack of a way to choose. It's overwhelming, and it leads to burnout.
Most content on AI authority signals reads like a packing list: here are all the things you might possibly need. That's helpful for orientation but completely useless for execution. What your team needs is a prioritization framework, something that tells you what to do Monday, what to do next quarter, and what to ignore until you've handled the first two.
That's what this is. This is the system I wish I had when I was starting.
The core argument here is simple: you don't need to optimize every authority signal. You need to sequence the highest-leverage signals first for the specific prompts you need to win, then build a feedback loop so you always know what to fix next.
What are "AI search authority signals" (and how are they different from SEO ranking factors)?
What "authority" means in AI answers: being cited, recommended, or named
Let's get this straight. Traditional SEO is about ranking on a page. AI search is about being part of the conversation. When ChatGPT answers a prompt, it synthesizes an answer and decides which sources to attribute. Your goal is to be named or cited in that answer. Page one doesn't exist in a chat. Being mentioned, cited, or named in an AI-generated answer is the new target. It's a whole new game.
Brand authority vs topical authority (and why you need both)
I see people mix these up all the time. They are two different levers. Brand authority is your market standing, which you can see in branded searches and PR. Topical authority is your depth on a subject, proven by extensive, useful content. You absolutely need both. I once worked with a company that had amazing brand authority, tons of press, but no deep content. They'd get mentioned as a player in the space, but their content was never actually cited as the source for an answer. The opposite is just as bad. All the topic depth in the world doesn't help if the AI doesn't see your brand as a credible entity.
The practical implication: you're optimizing for extraction and attribution, not just ranking
This changes how you write. AI systems extract citable claims. This means you have to structure your content for easy extraction. Think short, declarative answers early in your sections, named positions ("We recommend X for teams doing Y because Z"), and clear evidence. This is a shift in writing style, not just an optimization checklist.
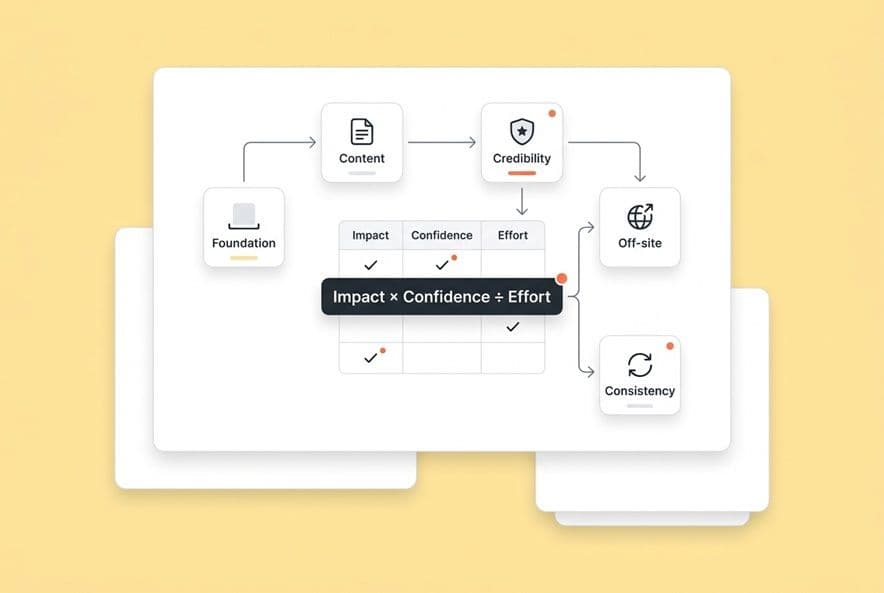
The 5-bucket map of authority signals (so you can stop treating them like one list)
Before you can prioritize, you have to get organized. Ditching the giant to-do list for a categorized map was a game-changer for my team. Here's the map we use for everything.
Foundation signals (crawlability, indexability, UX)
If AI platforms can't access and process your content, literally nothing else matters. This bucket covers the basics. Are your pages crawlable, indexed, and fast enough? Are you hiding content behind paywalls or JavaScript that doesn't render? Most teams just assume this is fine. Please, run the audit anyway. A surprising number of valuable pages get blocked by accident. You will be horrified by what you find. We always are.
Content signals (intent match, semantic depth, comprehensiveness)
This is about whether a page actually answers the question being asked with enough depth to be a useful source. Intent match means you're writing for what the buyer actually needs, not just some tangential keyword you want to rank for. Semantic depth means covering the topic so completely that an AI system sees your page as the go-to source on the subject, not just a surface-level overview.
Credibility signals (E-E-A-T, authorship, evidence, policies)
Experience, Expertise, Authoritativeness, Trustworthiness. AI systems are getting much better at reading these signals. This is about having named authors with real credentials, public editorial standards pages, and external sources cited within your content. Regular updates with visible dates help, too. These signals tell an AI model, "This source can be trusted."
Off-site signals (mentions, links, third-party validation)
Backlinks still matter, but the frame is shifting. The bigger question is, do authoritative third parties reference your brand and content? That includes links, but it also includes unlinked mentions in industry publications, podcast citations, analyst references, and community discussions. The signal is simple: "Other trusted sources vouch for this brand."
Consistency signals (brand voice, positioning, entity clarity across channels)
This one is so underrated. AI systems build entity models. They accumulate signals about who your brand is and what it stands for across all the places it appears online. If your blog sounds like one brand, your LinkedIn like another, and your PR quotes someone different again, that incoherence weakens your signal. Brand consistency isn't just a preference anymore. It's an authority input.
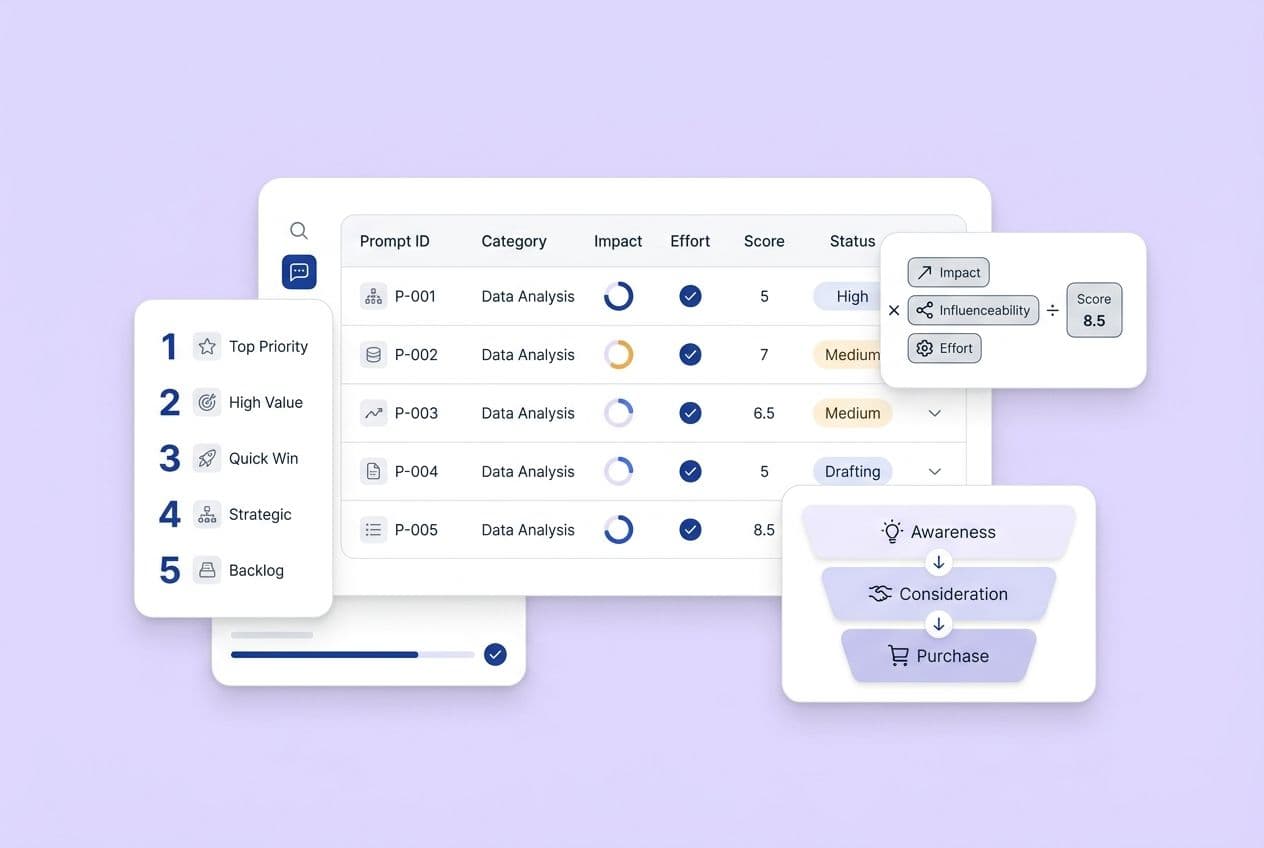
The prioritization scorecard: how to decide what to do first (Impact × Confidence × Effort)
Okay, this is the core of the framework. If you skimmed everything above, wake up for this part. This is how you escape the chaos.
Step 1 — Choose 10–20 "money prompts" you actually need to win
Don't try to optimize for "AI search" in the abstract. That's a recipe for failure. Pick the specific prompts your buyers are typing into ChatGPT, Perplexity, or Google's AI Mode right now.
For example: "What tool should I use to manage content operations for a small SaaS team?" or "How do I track whether my brand shows up in AI search?" or "Best alternatives to [competitor] for content marketing."
These are your money prompts. Write them down. Treat them like your most valuable keywords. Every decision you make from here on out should tie back to one question: does this improve my chances of being cited for one of these prompts?
Step 2 — Score each signal by likely impact on those prompts
For each signal you're considering (like improving author bios or building backlinks), estimate its impact on winning your money prompts. Use a simple 1 to 5 scale.
Let's be honest, you don't have exact data here. No one does. What you're doing is making your assumptions explicit so you can update them later when you get real data. A signal scores high on impact if the prompt type relies on it (credibility matters a lot for high-trust prompts), you're currently weak on it, or improving it unblocks other signals (like foundation signals do).
Add an Effort score (where 1 is months of work and 5 is done in a day) and a Confidence score (how sure are you this signal matters for your specific prompts?).
Your working priority score is Impact × Confidence ÷ Effort. The high scores are what you do first. Simple.
Step 3 — Add a "platform fit" modifier (Google vs ChatGPT/Claude vs Perplexity)
This modifier is important because different platforms weigh signals differently. You need to know which battlefield you're on before you commit your troops.
Google AI Overviews and AI Mode lean heavily on traditional SEO signals like indexed pages, structured data, E-E-A-T, and schema markup. If Google AI is your priority, your existing SEO work will pay off here.
ChatGPT and Claude are more likely to draw from sources they've seen cited broadly across the web, such as publications, industry references, and community content. They are less tied to real-time indexing and more influenced by their training data. This is where PR and brand mentions have more weight.
Perplexity acts more like a live search engine with a citation-focused UI. It indexes current content and shows its sources explicitly. Strong crawlability, fresh content, and authoritative off-site mentions all do well here.
Adjust your priority scores. If you're losing on Perplexity, weight off-site and technical signals higher. If Google AI Mode is the gap, double down on schema and structured content.
Operationally, the hardest part is knowing what's happening across these platforms without spending your whole day copying and pasting prompts. This is where prompt tracking tools earn their keep. A platform like DeepSmith's AI Visibility—Prompts lets you track your mention and citation rates across all the major players for your money prompts. It turns your platform-fit modifier from a guess into an observation.
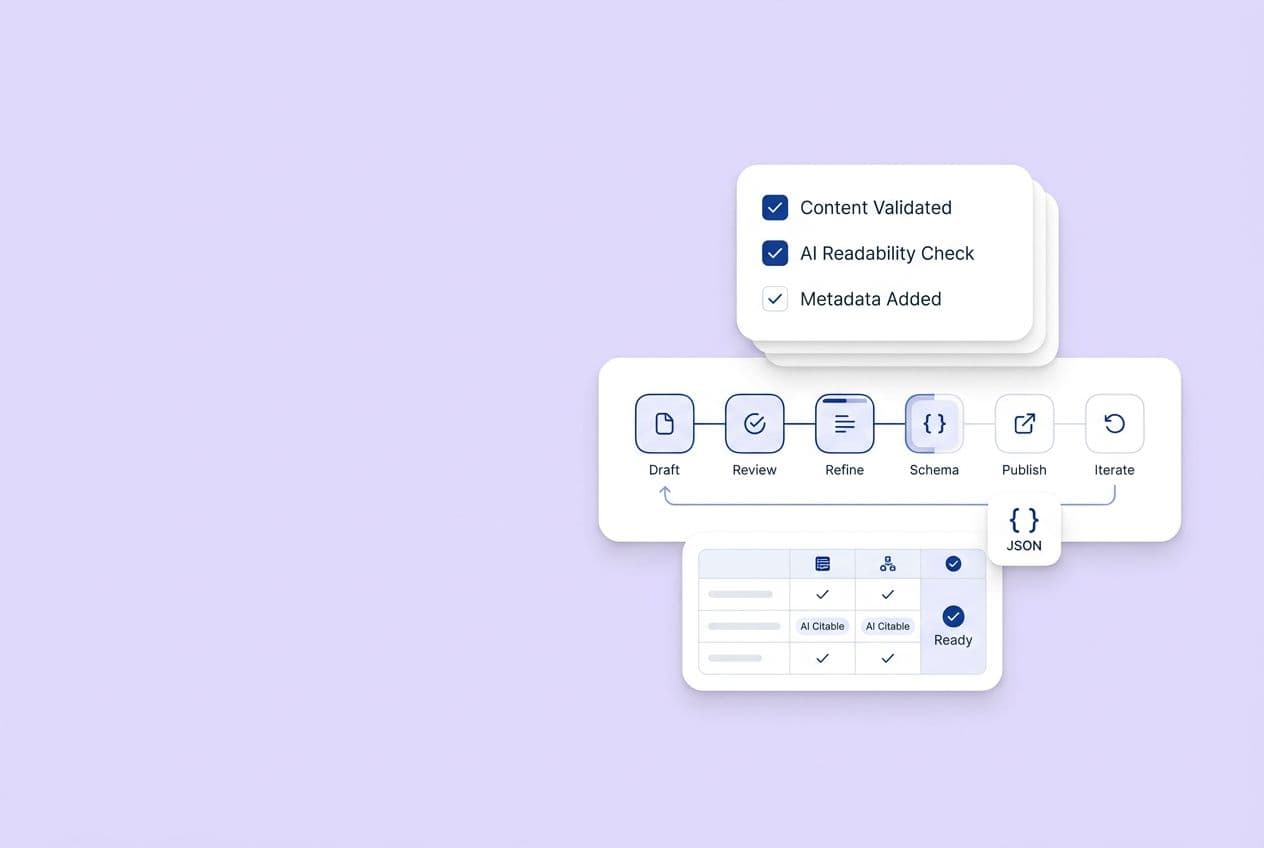
Step 4 — Convert scores into a 90-day sequence (foundation → credibility → coverage → amplification)
Here's the order that works for most teams I've seen, especially if you have limited bandwidth.
Days 1–30: Foundation + Quick Credibility Wins. Fix your crawl and index issues. Update author bios and add editorial standards. Make sure your top five pages are structured for extraction with answers first, clear headers, and named positions. This unblocks everything else.
Days 31–60: Content depth on money prompts. For each priority prompt, find the page that should rank for it. If it doesn't exist, create it. If it exists but it's shallow, expand it. Focus on semantic depth and that citation-ready structure.
Days 61–90: Off-site coverage + consistency audit. Start one systematic motion to build mentions. Audit your brand's voice consistency across channels. See who's winning citations on your prompts and figure out why.
Of course, a 90-day plan is only as good as your ability to execute it. The biggest drag on a sequence like this is usually the manual overhead of the content process itself. A connected workflow like DeepSmith's Content Studio is designed to reduce this friction. It bundles research, briefing, drafting, QA, and publishing into one system so your team can focus on strategy, not wrestling with a dozen disconnected tools.
A ready-to-copy table: common signals and how they typically score (with caveats)
Here's a cheat sheet I use. But please, treat this as a starting point, not gospel. Score this against your own money prompts and your current reality.
| Signal | Typical Impact | Typical Effort | Platform Fit | Priority Tier |
|---|---|---|---|---|
| Crawlability / indexing | High (unblocks all else) | Low–Medium | All | Tier 1 |
| Citation-ready content structure | High | Medium | All | Tier 1 |
| Author bios + E-E-A-T basics | High | Low | All | Tier 1 |
| Schema markup (FAQ, HowTo) | Medium–High | Medium | Tier 2 | |
| Semantic depth (topic expansion) | High | High | All | Tier 2 |
| Brand mentions (unlinked) | Medium | Medium | ChatGPT/Claude | Tier 2 |
| Earned backlinks (topical) | Medium | High | All | Tier 3 |
| PR coverage / analyst mentions | Medium | High | ChatGPT/Claude | Tier 3 |
| Brand voice consistency | Medium (long-term) | Low (governance) | All | Tier 2 |
| Multimodal assets | Low–Medium | High | Varies | Tier 4 |
*These are directional. Don't take my word for it; do your own scoring.
What "high-leverage" execution looks like for each signal bucket (tactical playbooks)
Foundation playbook: technical accessibility checks that unblock every other signal
Okay, let's talk about the unglamorous stuff that breaks everything. Run a crawl of your site with a tool like Screaming Frog or Ahrefs. Look for pages blocked in robots.txt that shouldn't be, valuable content that only renders client-side, and core pages with slow mobile load times. Fix the blocking issues first. One indexed page is better than ten optimized pages that AI systems can't even read.
Content playbook: building citation-ready sections (answers first, structured claims, scannable proof)
I see so many teams write beautiful, poetic content that is completely useless to an AI. Write for extraction. Every section of your priority pages should open with the direct answer and then support it. Use this structure: Position statement → supporting reasoning → specific evidence or example → implication. Lead with definitions in dedicated pages (AI systems love clear definitions). Use comparison tables because they are highly extractable. Name your positions explicitly, like "Our recommendation for teams under 50 people is X, because Y." Vague content doesn't get cited. Specific claims do.
Credibility playbook: E-E-A-T assets that content teams can control
These are the most impactful credibility signals your team can control directly, and they aren't even that hard.
- Named, linked author bios with real credentials and verifiable experience.
- Visible update dates on every page (and actually update the content, don't just change the date).
- Outbound citations to reputable sources within your content to show your work.
- An editorial standards or methodology page that explains how you research and fact-check.
- Review or contribution credits where external subject matter experts have weighed in.
Most of these take an afternoon to set up. It's a huge return on a small investment.
Off-site playbook: earning mentions that correlate with being "safe to cite"
Let's move beyond generic "do PR" advice. The highest-leverage mentions for AI visibility tend to come from a few places.
- Industry roundup posts on authoritative sites (pitch to be included as a resource).
- Podcast appearances where your team is named as experts (the transcripts get indexed).
- Community contributions, meaning thoughtful, detailed answers on Reddit, Slack communities, and niche forums.
- Analyst or media relations where you're positioned as a category voice, not just another vendor.
Pick one motion and run it for 60 days. Measure if your mentions increase before you add another.
A quick note on volatility. Sources like community forums can be powerful but also unpredictable. A viral thread can drive great visibility one week and be gone the next. Don't build your core strategy on chasing these. Treat them as a bonus layer on top of durable citations from publications, podcasts, and analysts. Focus your effort on sources with real editorial staying power.
Consistency playbook: preventing voice/positioning drift at scale (human + AI)
Every piece of content your brand publishes either strengthens or weakens your entity signal. To keep it strong, document your brand's core positioning claims (not just your voice), define what your brand always says and what it never says, and build a lightweight QA checkpoint into your workflow to check for drift.
This is especially critical if you use AI-assisted writing. Generic AI output doesn't just sound bad; it actively weakens your entity clarity because it sounds like everyone else. The solution isn't to stop using AI. It's to ground it in structured brand context before it writes a single word. Tools like DeepSmith's Deep IQ layer store this context (like positioning, voice rules, and persona details) and inject it into every draft. This way, you aren't re-briefing every article or just hoping writers remember the style guide.
How to handle multimodal authority (images/video) without turning it into a production tax
When multimodal is worth it (and when it's a distraction)
Everyone's telling you to do video, right? Let's talk about when it's actually worth the headache. For most SaaS teams, multimodal is a Tier 4 priority. You address it after your foundation, content, and credibility signals are solid. It's worthwhile when queries are inherently visual (like UI walkthroughs), when video boosts dwell time on a key page, or when competitors are winning with visual assets. Otherwise, it's a distraction from more critical work.
A scalable approach: reusable visuals, descriptive context, and page hygiene
The scalable way to do this is with high-quality, reusable assets that have proper context. Create a set of branded diagram templates you can update without a designer. Use custom screenshots instead of stock photos. And please, write detailed, specific alt text. Not "marketing team looking at dashboard," but a description of what the image actually shows and why it's there. One strong custom visual per page beats ten generic stock images every time.
Multimodal + structured data: how to make assets legible to machines
For AI systems to understand your visuals, they need to be machine-readable. This means descriptive alt attributes, image schema where it makes sense, video schema for embedded videos, and fast image load times. These aren't creative decisions. They are infrastructure choices that can take an afternoon to get right.
Measurement, ROI, and reporting: proving AI authority work is paying off
The KPI stack: prompt-level visibility, page-level citations, and business proxies
Clicks from AI search are going down as a share of outcomes. If you only report on traffic, your AI authority work will look like it's failing even when it's winning. You need a three-layer KPI stack instead.
Layer 1 — Prompt-level visibility: For your money prompts, track your mention rate (do you appear at all?) and citation rate (do you appear with attribution?). This is your most direct signal.
Layer 2 — Page-level citations: Which specific pages are earning AI citations? Are they trending up or down? This tells you what's working. DeepSmith AI Visibility—Pages is built for this. It shows you which content pages are earning citations so you can prioritize updates.
Layer 3 — Business proxies: Things like branded search volume trends, direct traffic, and pipeline attribution where possible. These take longer to move, but they're the language leadership understands.
A monthly reporting template: what changed, why it changed, what we'll do next
Keep your monthly reports simple and focused on these three questions.
- What changed? (Mention and citation rate movement for your prompts).
- Why did it change? (Content updates, competitor moves, platform shifts. Be honest about what you know versus what you're inferring).
- What's next? (A specific action tied to the data. Not "continue to optimize," but "update [specific page] to improve its structure for [specific prompt]").
This format keeps the conversation focused on decisions, not just staring at metrics.
ROI reality check: what you can claim confidently vs what stays directional
Be honest with your leadership. We all want to draw a straight line from our work to revenue, but it's not that simple here. You can confidently claim citation rate changes for tracked prompts and page-level citation trends. You can directionally claim a correlation between AI visibility and pipeline trends over time. You cannot claim exact revenue attribution from a single citation to a closed deal. The chain is too long and messy. Name that limit proactively. It builds more credibility than pretending the data is cleaner than it is.
When your AI visibility drops: a remediation checklist (and the questions to ask vendors/tools)
Diagnose by bucket: technical, content, off-site, consistency, competitor velocity
When visibility drops, the first instinct is to publish more content. Resist that urge. Diagnose the problem first.
- Technical: Did a recent deploy accidentally block crawlers? Did page speed get worse? Run a crawl and check your robots.txt.
- Content: Was a high-performing page changed or shortened? Does it still have an extraction-ready structure?
- Off-site: Did a major source that cited you go away? Did a community thread that referenced you get deleted?
- Consistency: Did a wave of new content go live that sounds like a different brand?
- Competitor velocity: Did a competitor just publish a ton of content on your money prompts? Are they winning the citations you used to have?
DeepSmith AI Visibility—Competitors helps with that last one. It tracks which competitor pages are earning citations so you can detect surges early.
"Fix vs build": deciding whether to update existing pages or publish new ones
Here's my simple rule: if a page already exists for the prompt and has some citation history, update it first. Refreshing a page with established authority is almost always faster than building it from scratch. Only publish new content if the gap is real and you have nothing that covers it.
Tool/vendor questions that reveal whether a solution will actually work for your team
When you're evaluating AI visibility tools, here's how to cut through the noise. Ask these questions.
- Does it track actual mention and citation rates (not just rankings), across multiple AI platforms?
- Does it connect visibility data to your content workflow, or is it just another reporting dashboard?
- How quickly does it detect changes in competitor citation activity?
- What does setup actually look like, and what does ongoing maintenance require from my team?
If a vendor can't give you a clear answer to that second question, their tool will become another data source you check once a month and never act on. The real value is in connecting visibility gaps to content decisions you can make this week.
Build your AI authority roadmap (and execute it without adding headcount)
This framework should give you a way to make decisions, not just a bigger to-do list. Score your signals against your money prompts. Sequence by tier. Run a 90-day sprint with a real owner and clear goals. Then build the feedback loop that tells you what to do next.
The teams that will own AI search citations aren't the ones who did everything. They're the ones who did the right things first and built a repeatable system.
If you want to turn this framework into an operational workflow (with prompt tracking, citation measurement, and a content pipeline that moves without becoming a second job), that's what DeepSmith is built for. Track your gaps, produce the content that closes them, and measure if it's working, all in one place.