Your competitor just showed up in a ChatGPT answer for the exact question your buyers are asking. You searched. You're not there. And now leadership is asking what your AI search strategy is. The honest answer? You don't have one yet.
I've been there. It's a terrible feeling.
Here's the deal: most E-E-A-T audits won't fix that problem. They'll have you checking author bios, verifying your HTTPS, and adding a citation or two, then calling it a day. That's hygiene, not strategy. And hygiene doesn't get you cited by Perplexity.
What actually earns AI citations is different from what earns blue links. Answer engines are looking to extract specific, discrete answers from content. They evaluate if a source is credible enough to show a user who has a real question. They map topic authority across your whole site, not just one well-written page. The audit you need isn't a page-quality checklist. It's a citation-first audit that evaluates your content at four layers: the claim, the page, the cluster, and the site.
That's what I'm going to give you here. This is the repeatable, quarterly process we built out of necessity. It includes a scoring model, a measurement loop, and a realistic way to run it across a huge content backlog without losing your mind.
What is an E-E-A-T content audit (and what changes when the goal is answer engine visibility)?
What E-E-A-T is (a framework) vs. what you can actually measure (signals)
E-E-A-T stands for Experience, Expertise, Authoritativeness, and Trustworthiness. It's a framework Google's search quality raters use to evaluate content. It is not a direct ranking signal you can toggle, but a set of patterns that quality systems tend to reward over time.
The first mistake everyone makes is trying to "optimize E-E-A-T" as if it's a score you can top on a leaderboard. It's not. It's just a description of what trustworthy, credible content looks like. What you can measure are the signals that reflect it. Things like claim precision, author credentials, source citations, topic coverage, internal linking, and site-wide transparency. Those are concrete. Those are auditable.
This audit focuses on those measurable signals, not abstract quality ratings.
Why answer engines reward different "units" than Google SERPs (claims, not pages)
Google rewards pages. Answer engines reward answers.
When ChatGPT or Perplexity generates a response, it pulls discrete, attributable statements from content it trusts. It's looking for claims that are clear enough to extract, sourced well enough to surface, and specific enough to actually answer a question. I learned this the hard way. We had a 2,000-word article with great traffic, but it buried its most useful insight in paragraph nine. It never got cited.
This is the key shift in thinking: your audit unit is the extractable claim, not the page. Pages that earn AI citations tend to have clearly structured answers, concrete supporting evidence, and unique insights you won't find rephrased on five other sites.
The core outputs of this audit (scorecard, prioritized backlog, measurement loop)
When you're done, you won't just have a bunch of notes. You should have three things that make up a real system:
- A scored content inventory: a spreadsheet of every URL evaluated for claim quality, page trust, cluster coverage, and site-wide hygiene.
- A prioritized remediation backlog: your to-do list, organized by effort versus impact, so you're fixing the pages most likely to earn citations first.
- A measurement loop: a defined set of prompts and baseline readings so you can tell whether your work is actually moving the needle on AI visibility.
Without all three, you just have observations. With them, you have a system.
What answer engines are most likely to cite: the 4-layer E-E-A-T model (claim, page, cluster, site)
This is the framework the rest of the audit runs on. E-E-A-T doesn't live in one place. It operates at four distinct layers, and weakness at any layer can tank your citation chances, even when the others are strong.
Claim-level E-E-A-T: "Is this answer citable?"
This is where most audits don't go, and it's where most citation problems start.
A citable claim has four properties:
- Discrete: It answers one specific question, not five vague ones.
- Attributable: There's a reason to trust this source for this claim, like data, a clear method, real practitioner experience, or a logical argument.
- Non-generic: It can't be found rephrased identically on 10 other sites.
- Extractable: It's structured clearly enough that a language model can pull it without mangling its meaning.
Go through your top pages and highlight the sentences that actually answer a reader's question. How many of them pass all four tests? For most of us, the honest answer is fewer than we'd like. Introductory paragraphs that restate the question, body sections that hedge every claim, and conclusions that just summarize are common. None of that gets cited.
The audit check is simple: can I pull a single sentence or paragraph from this page that directly answers a real buyer question with something defensible and non-obvious? If not, that's your first target for remediation.
Page-level E-E-A-T: "Can I trust this page as a source?"
Once you have strong claims, the page itself needs to feel credible. Page-level trust signals include things like:
- Author attribution: a named author with credentials relevant to the topic, not just a headshot.
- Publication and update dates: they need to be clearly visible. An outdated date on a page making a time-sensitive claim is a major red flag.
- External sources: links to credible primary sources like studies, documentation, or established reporting.
- Content structure: clear headings, readable formatting, and a logical flow that doesn't make the reader hunt for the answer.
- Page health: good load speed, proper mobile rendering, and no broken links.
Using structured data (like Schema markup) can also help by explicitly labeling key info like the author and publication date, making it easier for systems to parse these trust signals. None of this is exotic stuff. But it's easy to let author details or "last updated" dates go stale. For answer engines, those signals matter because they're proxies for editorial accountability.
Cluster-level E-E-A-T: "Do you own this topic area?"
A single great article doesn't make you an authority. A cluster of well-structured, interlinked content that covers a topic from all angles signals that your domain genuinely understands the territory. That means having an overview, subtopics, comparisons, implementation details, and edge cases covered.
Answer engines infer expertise from coverage depth. If you have one good article about customer onboarding metrics but nothing about onboarding benchmarks, how to build onboarding flows, or what causes onboarding drop-off, you're not signaling topic ownership. You're signaling that you wrote one article.
The cluster audit looks at whether your most important topic areas have real depth, including a hub piece, supporting spokes, and visible internal links connecting them. Gaps in your coverage are gaps in your perceived authority.
Site-level E-E-A-T: "Does this brand look real and accountable?"
Before any of the above matters, the site itself needs to pass a basic credibility check. This is the hygiene layer. It's necessary but not sufficient.
- HTTPS on every page
- A clear "About" page with company and team information
- A privacy policy and terms of service
- Contact information that goes to a real person
- Consistent brand identity across your site
If these are missing or incomplete, fix them first. They aren't differentiators, they're prerequisites. AI systems and human raters use these signals to figure out if a site is a real, accountable organization or just a content farm.
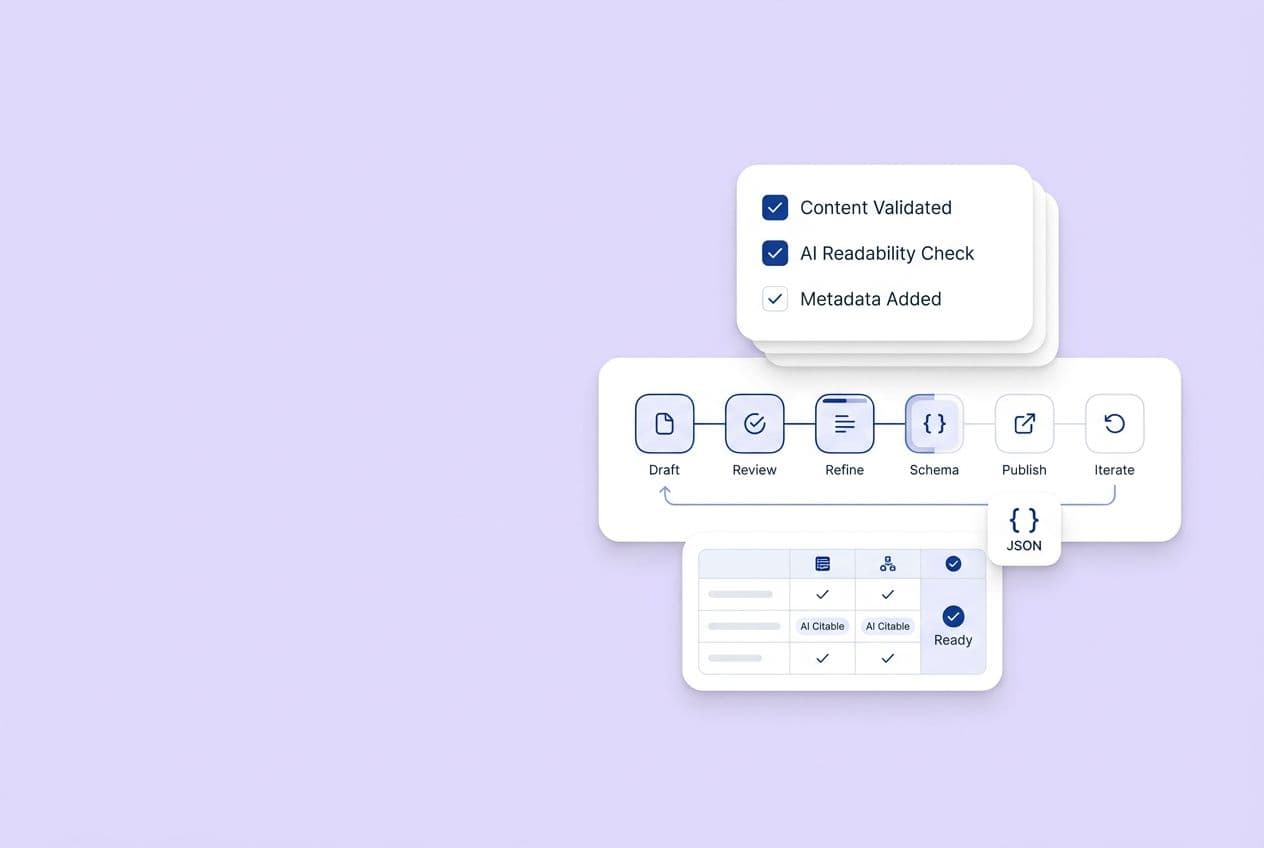
How to perform an E-E-A-T content audit for answer engine visibility (step-by-step)
Step 1 — Define your "citation targets": prompt set, topics, and pages in scope
Let's be real, "improving AI visibility" is a meaningless goal. You can't measure it. Start by defining the 10 to 20 questions your buyers actually ask AI tools when they're researching. These become your prompt set, the baseline you track over time.
Once you have those prompts, identify the content you already have (or need to create) that should be answering them. These pages are your priority for the audit. Everything else can be audited in batches later.
Step 2 — Inventory and segment content by intent, risk (YMYL), and cluster
Pull a full content inventory with the URL, title, topic, publish date, traffic, and backlinks for each piece. Then, segment it all by:
- Topic cluster: which hub does this page support?
- Content intent: is it informational, a comparison, or product-led?
- YMYL-adjacent risk: does this content touch on financial, legal, health, or safety decisions? For these topics, the audit has to be stricter. It demands verifiable author credentials (like medical or financial certifications), a higher standard of evidence, and clear disclaimers. What might be a 'pass' on a normal SaaS post could be a 'fail' here if the sourcing isn't ironclad.
Segmenting by cluster lets you batch your audit work and spot gaps much faster than reviewing URLs one by one.
Step 3 — Audit at the claim level: extract answers, check evidence, check uniqueness
For each priority page, do this exercise. Read the article and pull out every sentence that directly answers a real question. Then run each one through the citable-claim checklist:
- Is it discrete and specific?
- Is there evidence or a clear logical basis for it?
- Is it unique, or does it just say what every other source says?
- Is it formatted clearly enough to be extracted?
Note which claims pass and which fail. Pages where most claims fail are candidates for a rewrite. Pages where just a few sections fail are update candidates.
Step 4 — Audit page trust & usability: author, sources, updates, transparency
For each page, check for:
- A named author with a bio linked to their credentials
- Visible publish and update dates
- At least two or three credible external sources cited where claims need them
- No broken links or missing images
- A load time under 3 seconds on mobile
Create a simple score (pass/partial/fail) for each item. Pages with multiple partials or fails need attention before their claims can be taken seriously.
Step 5 — Audit cluster coverage & internal linking: identify "authority gaps"
For each of your core topic clusters, map out the subtopics that should exist. Compare that map against your inventory. What's missing? What's thin? Where are the hub pages that should be tying it all together?
Then check your internal linking. Does the hub page link to all the major spokes? Do the spokes link back to the hub and to each other where relevant? Broken or missing internal links limit how much authority flows through the cluster and how clearly AI systems can see your topic coverage.
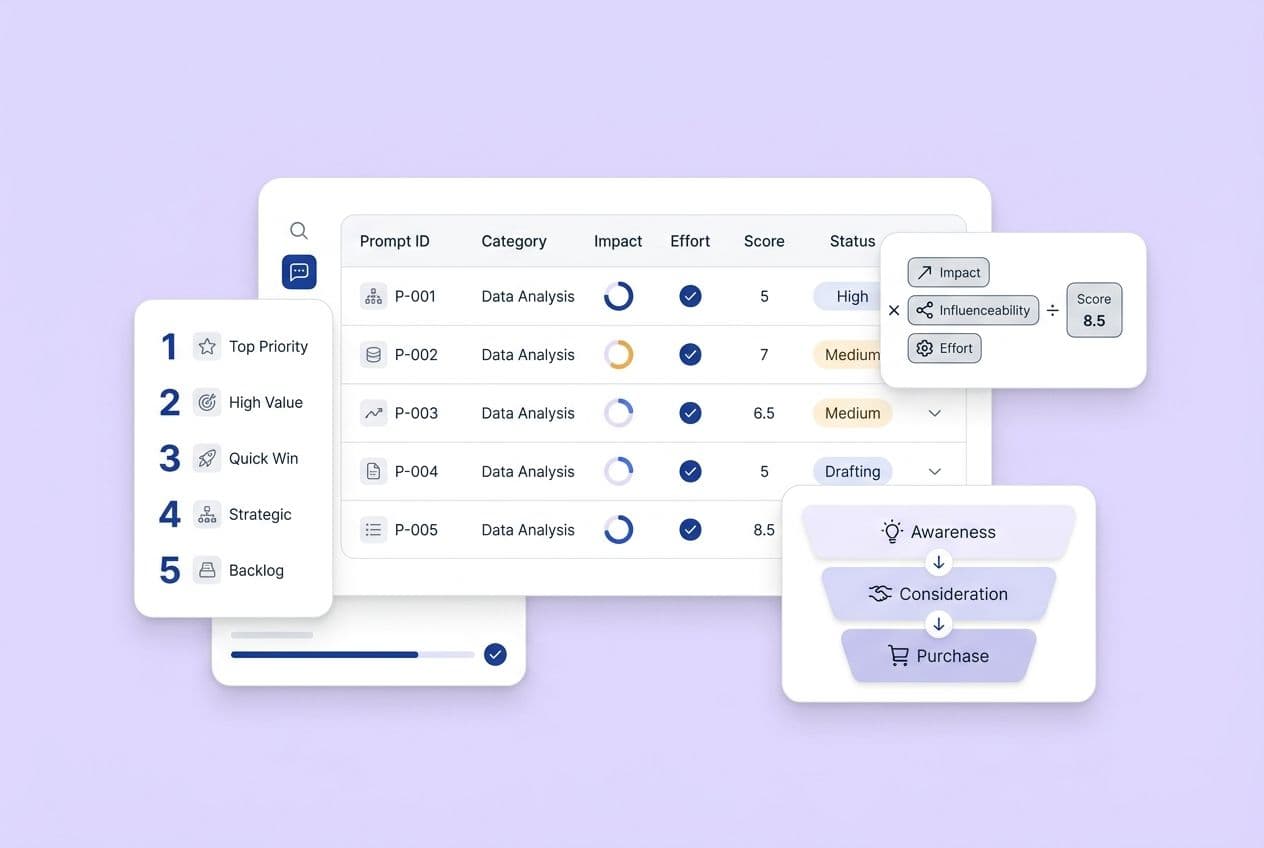
Step 6 — Score, prioritize, and create a remediation backlog (quick wins vs. rebuilds)
Combine your findings into a single spreadsheet. Score each URL across the four layers (claim, page, cluster, site). Then flag pages as:
- Quick wins: Strong traffic, good intent match, minor fixes needed (like updating a date, improving one claim, or adding a citation).
- Rebuilds: Important topic but weak execution that needs a substantive rewrite.
- Merge candidates: Overlapping coverage with another page, which splits your authority.
- Archive: Low traffic, outdated, and no clear value in keeping it.
Seriously, work the quick wins first. They move the needle faster and keep momentum going, which is critical when you're managing a backlog on top of everything else.
A practical scorecard and checklist your team can run at scale
The scorecard categories (claim, page, author, cluster, site)
Use a simple 0 to 2 scale for each check, where 0 is failing, 1 is partial, and 2 is passing.
| Layer | Check | Score |
|---|---|---|
| Claim | Contains at least one discrete, attributable answer | 0–2 |
| Claim | Supporting evidence or logical basis present | 0–2 |
| Page | Named author with relevant credentials | 0–2 |
| Page | Publish/update date visible and accurate | 0–2 |
| Page | External sources cited where needed | 0–2 |
| Author | Bio links to verifiable credentials or work | 0–2 |
| Cluster | Page links to cluster hub | 0–2 |
| Cluster | Hub page links back to this page | 0–2 |
| Site | About, privacy, contact all present and complete | 0–2 |
The total possible score is 18. Any pages scoring below 10 go into the active remediation queue. Pages scoring 14 or higher are candidates for light optimization only.
What "good" looks like for Experience in B2B (without fake anecdotes)
For years, I thought "experience" meant we had to have these slick, first-person case studies for everything. It was exhausting. It turns out, that's not it. Experience signals in B2B content don't require war stories. They require artifacts, the kind of detail that only comes from someone who has actually done the work.
- Decision criteria: "We chose X over Y because of Z constraint, not because Y is worse overall."
- Failure modes: "This approach breaks when the dataset exceeds 10K rows. Here's what to do instead."
- Implementation specifics: Screenshots, config examples, or actual output samples.
- Benchmarks from practice: "Teams running this process typically see the first meaningful results at week six, not week one."
- What the documentation leaves out: The gaps, caveats, and edge cases practitioners discover that official sources don't mention.
When auditing for Experience, the check is simple: does this page contain details a practitioner would know that a researcher wouldn't? If everything on the page could have been written by reading three other articles, it fails the Experience test.
Red flags that suppress trust and citations
These are the patterns that get your content skipped by answer engines:
- Thin pages: Under 600 words on a complex topic, or pages that just restate the question.
- Outdated claims: Statistics from three years ago presented as current.
- Contradictory posts: Two articles on your site giving different answers to the same question. An AI system resolves this by not citing either of them.
- Un-sourced assertions: Strong claims (like benchmarks or percentages) stated as fact without any evidence.
- Generic intros: Long wind-ups that delay the actual answer. AI extraction rewards pages where the answer appears early and clearly.
How to audit author credibility when multiple writers contribute
Most of us have multi-contributor blogs, and they create credibility drift. You'll have a detailed bio for your Head of Content and a placeholder bio (or none) for every freelancer.
Standardize your author requirements for everyone:
- Full name and job title or domain description.
- Two or three sentences on relevant experience (just enough to prove they've worked in this space).
- A link to their LinkedIn or portfolio.
- For technical topics, explicit notation of credentials, certifications, or years of practice.
For posts written by freelancers or AI-assisted drafts, include an editorial accountability line like "Reviewed by [Name], [Title]" so there's a named human attached to the claims. This matters more for high-stakes topics but is good practice everywhere.
Trying to enforce this at scale, especially during big remediation projects, is tough. A structured context layer is key. For example, platforms like DeepSmith's Deep IQ can store your author guidelines and apply them automatically, which helps reduce the credibility drift from having eight different people working on pages.
Content architecture and internal linking strategies that strengthen E-E-A-T site-wide
Build "topic ownership" with hub/spoke clusters
Every core topic you want to be cited for needs a hub article. This is a comprehensive, well-structured piece that answers the primary question, surrounded by spoke articles that go deep on subtopics and link back to the hub.
The hub earns broad authority and gives AI systems a landing point. The spokes demonstrate your depth and pass relevance signals back up the chain. Without both, you have a collection of posts, not a real topic cluster.
When linking spokes to hubs, use descriptive anchor text that reflects the subtopic, not generic "click here" links. The anchor text is part of how AI systems understand the relationship between your pages.
Use internal links to prove depth, not just to pass PageRank
People often think internal links are just for passing equity from old pages to new ones. That's true, but it's only half the story. Internal links also map your domain's intellectual territory. They show which topics connect, where your expertise overlaps, and how thoroughly you cover an area.
For answer engine visibility, think of your internal link structure as the evidence that you're the right source for a whole topic, not just one article. We once found a critical article about a core feature that had zero internal links pointing to it. It was an orphan. To us, it was important, but to any AI trying to understand our site, it might as well have not existed. That was a painful but valuable lesson.
Maintaining this architecture manually across a large site is genuinely hard. This is another spot where tools can save you. For example, DeepSmith's automatic internal link insertion can scan your sitemap and place contextually relevant links during the writing process, building the architecture in rather than retrofitting it later.
Common architecture mistakes
- Orphan pages: Content with no internal links pointing to it. It exists in your CMS but not in your authority structure.
- Scattered definitions: If you define "customer health score" differently in three different posts, you've created a trust problem.
- Duplicate angles: Two posts answering the same question from nearly identical angles. This splits your authority instead of concentrating it. You should merge them or differentiate them clearly.
How to remediate low E-E-A-T pages: update, merge, rewrite, or remove (and how to recover trust)
The 4 remediation actions and when each is the right call
- Update: The page has strong bones and good intent match, but just needs fresher data, a new example, or an additional section. Use this when traffic or link equity already exists.
- Merge: You have two or more pages covering overlapping territory. Combine the best material into one stronger post and 301 redirect the others.
- Rewrite: The topic is important and has high-intent keywords, but the current execution is weak. Start fresh using your audit findings as the brief.
- Remove/Archive: The page has low traffic, is outdated, has no link equity, and no clear user value. A smaller, stronger content library is better than a large, mediocre one.
Default to updating and merging before you commit to full rewrites. Rewrites are expensive, and the risk of accidentally making things worse is real.
How to fix Experience/Expertise gaps with stronger evidence, examples, and constraints
When a page fails the Experience check, the fix is almost always adding, not replacing. Add a section that covers:
- What goes wrong: The failure modes and edge cases that practitioners run into.
- What the decision actually looks like: Not "consider your options," but "if X, choose Y; if Z, choose W, because of this specific tradeoff."
- What you'd look for in practice: Real evaluation criteria, not theoretical ones.
You don't need to invent anecdotes. Real practitioner experience shows up in specificity and constraint. The more precisely you define when something works and when it doesn't, the more credible your claim becomes.
How to handle negative trust signals (outdated advice, contradictions, shaky claims)
Outdated posts and contradictory claims erode credibility even if your newer content is strong. You have to fix this proactively.
- Do a contradiction audit. Search your site for posts on the same subtopic, compare the positions they take, and align them.
- Add update banners to posts with old data if you can't immediately update it. Transparency about staleness is better than confidently presenting old information.
- Remove internal links that point to outdated or contradictory posts until you can fix them.
How to use AI responsibly in remediation without lowering credibility
AI tools can speed up remediation, but they shouldn't run the show. Here's a hybrid workflow that actually works:
- Use AI to generate a first-pass outline for a rewrite based on your audit findings.
- Have a human with domain knowledge validate the structure and add the Experience-layer specifics.
- Use AI to draft body sections based on the approved outline.
- Have a human editor do a final pass for claim accuracy, voice consistency, and sourcing.
Platforms like DeepSmith Content Studio can run this as a connected pipeline, from research and brief to draft and QA. This helps ensure your audit findings actually become published updates instead of sitting in a forgotten document.
How to measure whether your E-E-A-T audit is improving answer engine visibility
Baseline first: prompts, platforms, and what "visibility" means (mentions vs. citations)
Before you can measure improvement, you need a baseline. Define it precisely.
- Your prompt set: The 10 to 20 buyer questions you defined in Step 1.
- Your platforms: At a minimum, check ChatGPT, Perplexity, and Google's AI Mode.
- Your metrics: Track both mention rate (your brand name appears in the response) and citation rate (a specific URL is linked or referenced).
Run your prompts before you make any changes and log the responses. This is your starting point.
Tracking this consistently is the part that breaks down for most teams. Running 20 prompts across multiple platforms every month by hand is a massive time sink. This is where tracking suites like DeepSmith's AI Visibility become invaluable. You can define your prompts, track rates automatically, and tie citation changes directly to the content updates your team made. It turns a vibes-based assessment into a real feedback loop.
Page-level attribution: connecting citations back to specific URLs and clusters
When your citation rate improves, you need to know which pages earned the citations and why, so you can do it again. Track:
- Which URLs appear in AI responses for which prompts.
- Whether those URLs changed after your remediation work.
- What those pages have in common structurally (like claim format, content length, or topic cluster).
Over time, this tells you what "citable" looks like for your specific domain, which helps you brief and prioritize new content.
A simple reporting cadence and review ritual (monthly + quarterly)
- Monthly: Run your prompt set, log citation rates, and note any page-level changes.
- Quarterly: Run a full audit cycle. Reassess your scored inventory, update the backlog, review cluster coverage, and archive or update anything that's decayed.
- Annually: Reassess your topic cluster strategy, consolidate overlapping content, and update your prompt set to reflect how buyer questions are evolving.
The quarterly cadence is what turns this from a one-off project into a compounding system. E-E-A-T isn't a state you achieve, it's a standard you maintain.
Turn your audit into a repeatable system
Running this audit once is useful. Running it quarterly is how you build compounding authority in answer engines.
Here's the minimum viable system you can start this week:
- Set your prompt baseline: Define 10–15 buyer questions, run them across ChatGPT, Perplexity, and Google AI Mode, and log what comes back. This is your starting point.
- Prioritize your first audit sprint: Pull your top 20 pages by traffic or strategic importance, run them through the four-layer scorecard, and flag quick wins versus rebuilds.
- Ship the quick wins first: Update dates, improve a claim, add a missing author bio, or fix a broken link. Momentum matters more than perfection.
- Schedule the quarterly review: Block the time now. An audit that exists in your calendar gets done. The one you plan to do "when things slow down" never happens.
The teams that figure out AI visibility over the next 12 months won't be the ones who obsessed over it. They'll be the ones who built a repeatable process and ran it consistently. That's what this audit gives you. Now go run it.